📌Linux 主机检查 💻
常用
| 功能 | 子项目 | 命令 | 其他 |
|---|---|---|---|
| CPU | - | htop | |
| GPU | - | nvidia-smi | 还可以用 gpustat/ nvitop |
| 磁盘 | - | iostat | 新版本的 htop 同样可以监控磁盘 I/O(在 3.2.2 版本上测试可以,老版本 2.2.0 上实测不行) |
| 网络 | - | ||
| ↑ | 端口 | sudo netstat -pnltu | 还可以用 sudo ss -nltup,快得多(不加 sudo 可能会少显示一些程序的端口号、名字等) |
| ↑ | 不同连接的网速 | sudo iftop | |
| ↑ | 具体接口的不同连接的网速 | sudo tcptrack -i eno1 | |
| ↑ | 具体端口的网络活动 | tcpdump -i any port 53210 |
注意 docker 容器内的端口号和容器外的端口号是不同的。
2025/4/14 推荐 btop,不需要 root 权限就能查看当前网速。btop 也还有其他的功能,看起来想和 htop 争。
2025/4/18 推荐 安装 sysstat 获取 CPU/ 磁盘 / 网络统计日志,防患于未然。
GPU
nvidia-smi 就不说了,N 家自己的工具。默认的会读很多信息,如果只需要显存信息,可以用 nvidia-smi --query-compute-apps=pid,process_name,used_memory --format=csv,这样输出的速度也更快,差不多 87 ms。
gpustat 来自同名 pip 包,最主要的好处是它显示的方式更加紧凑,便于配合 watch 命令在小窗口不断刷新(偷懒不用 nsys / nsight-sys 而是直接看显卡整体情况)。比如 watch -n 0.5 -c gpustat -cp --color。而 nvidia-smi 就会遇到显示不下,只能看到窗口上半部分的情况。不过 gpustat 的速度较慢,在 7 卡的服务器上测试,nvidia-smi 输出耗时 210 ms,而 gpustat 输出耗时 930 ms,因此可能会跟不上 watch 指定的执行频率(watch 的逻辑是执行完当前命令之后等待给定的 interval,然后再执行新程序,所以并不会出现进程启动过多的问题;同样地,如果进程速度太慢,间隔应该给 0.1,这也是 watch 支持的最低间隔时间了)。
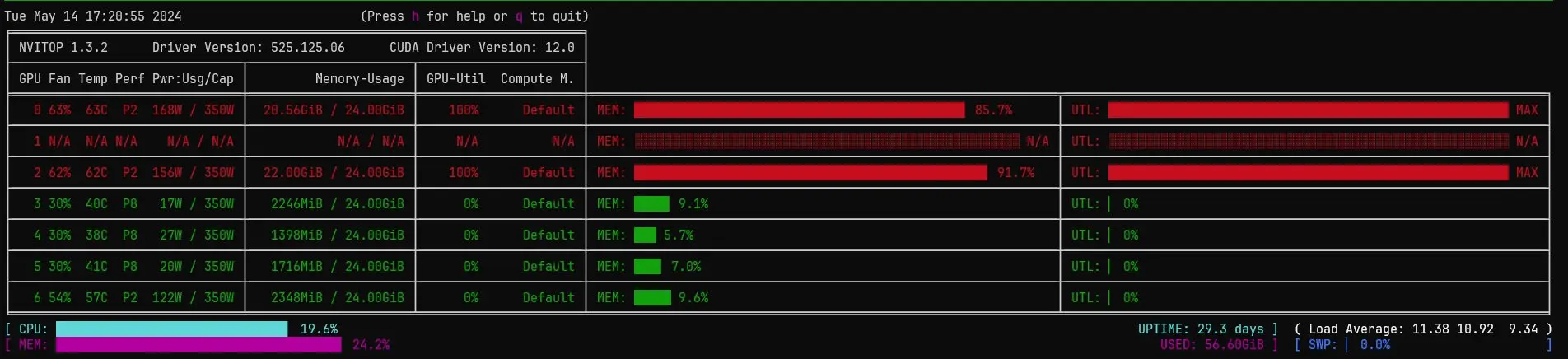
nvitop 也来自于同名 pip 包,本身就是 watch 模式,但是同样需要一个较大的面板才能完整显示。如果出现了 No Such Process 的情况,需要升级 nvidia-ml-py 到兼容当前 GPU 驱动的版本(没有成功,连 nvidia-smi 自己使用 –query-compute-apps 查出来的结果也是有 No Such Process 的)。
2024 年 5 月 14 日,我们服务器的 CI 无法启动新容器,一看容器中 nvidia 脚本报错说 nvml 有错。看服务器 nvidia-smi 报错、gpustat 也报错,pytorch 能够计算但是有警告。
(base) xxx@yyy:~$ gpustat
Error on querying NVIDIA devices. Use --debug flag for details
(base) xxx@yyy:~$ nvidia-smi
Unable to determine the device handle for GPU0000:1C:00.0: Unknown Error
但是 nvitop 竟然能正常工作!一看是卡 1 坏掉了。
这后面检查都有一些事后诸葛亮的意味了。。。
用 dmesg 看日志,和 nvidia-smi 的报错相符:
[2528444.953499] NVRM: Xid (PCI:0000:1c:00): 79, pid='<unknown>', name=<unknown>, GPU has fallen off the bus.
[2528444.953511] NVRM: GPU 0000:1c:00.0: GPU has fallen off the bus.
[2528444.953523] NVRM: A GPU crash dump has been created. If possible, please run
NVRM: nvidia-bug-report.sh as root to collect this data before
NVRM: the NVIDIA kernel module is unloaded.
检查之前 nvidia-smi 报错的卡是哪一张,发现的确是卡 1:
(base) amax@node148:~$ lspci | grep NVIDIA
1b:00.0 VGA compatible controller: NVIDIA Corporation GA102 [GeForce RTX 3090] (rev a1)
1b:00.1 Audio device: NVIDIA Corporation GA102 High Definition Audio Controller (rev a1)
1c:00.0 VGA compatible controller: NVIDIA Corporation GA102 [GeForce RTX 3090] (rev ff)
1c:00.1 Audio device: NVIDIA Corporation GA102 High Definition Audio Controller (rev ff)
1d:00.0 VGA compatible controller: NVIDIA Corporation GA102 [GeForce RTX 3090] (rev a1)
1d:00.1 Audio device: NVIDIA Corporation GA102 High Definition Audio Controller (rev a1)
1e:00.0 VGA compatible controller: NVIDIA Corporation GA102 [GeForce RTX 3090] (rev a1)
1e:00.1 Audio device: NVIDIA Corporation GA102 High Definition Audio Controller (rev a1)
3d:00.0 VGA compatible controller: NVIDIA Corporation GA102 [GeForce RTX 3090] (rev a1)
3d:00.1 Audio device: NVIDIA Corporation GA102 High Definition Audio Controller (rev a1)
40:00.0 VGA compatible controller: NVIDIA Corporation GA102 [GeForce RTX 3090] (rev a1)
40:00.1 Audio device: NVIDIA Corporation GA102 High Definition Audio Controller (rev a1)
41:00.0 VGA compatible controller: NVIDIA Corporation GA102 [GeForce RTX 3090] (rev a1)
41:00.1 Audio device: NVIDIA Corporation GA102 High Definition Audio Controller (rev a1)
就是因为这一张坏卡存在,nvml 无法正常初始化。目前怀疑这张卡是过热掉线。更新:重启果然就好了。
排查异常情况
日志一般存储在 /var/log 文件夹中,下面列举其中几类日志。
查看 journal 日志
sudo journalctl --since "3 days ago" | grep -i ssh
也可以使用 sudo journalctl -b 来查看上一次启动以来的日志(代替 --since 这种以时间来指定的)。
查看用户登录情况
查看当前谁在线用 who(1)。类似的有 w(1) - Show who is logged on and what they are doing.
查找历史登陆信息用 last(1)。而 lastb(1) 可以查看历史的失败登陆信息。
查看软件的安装
查看 apt 日志
# 查看 apt 历史
less /var/log/apt/history.log
# 查看被归档的 apt 历史
zless /var/log/apt/history.log.1.gz
apt 使用 logrotate 来完成日志轮替(rotate),具体配置见 /etc/logrotate.d/apt。其中,history.log 记录 apt 操作对系统带来的改动,term.log 记录每次操作的终端输出。
如果改动是用 dpkg 直接安装造成,或者用 aptitude 安装但缺失对应的日志文件(找不到 /var/log/aptitude,也找不到 aptitude 的配置项),就得直接检查 dpkg 的信息了。
检查 *.list 的修改日期
查看每个 dpkg 包的安装时间(参考 https://askubuntu.com/a/73181/ )比查看 dpkg 日志更简单:
# -t 选项将文件按照修改日期降序排列
# 此外可以通过 ls 的 --sort=[none|time|size|extension|version] 来排序
ls -lht /var/lib/dpkg/info/*.list
查看 dpkg 日志
通过日志文件查软件包的安装时间(参考 https://askubuntu.com/a/322406/1666727 ,不过原回答只能搜索非归档的日志文件):
ls --sort=version /var/log/dpkg.log.*.gz | tac | xargs zcat |
grep -E ' installed' - /var/log/dpkg.log*
具体的过程是:先解压二进制日志文件,然后将输出和文本日志文件一起交给 grep 搜索。/var/log/dpkg.log* 包括普通日志文件和轮替后的归档文件。这个 glob 模式会匹配上 *.gz,但是这些二进制文件几乎不可能匹配得上 " installed" 这个字符串。就算匹配上了,也只是会打印一条二进制文件 XX 匹配的信息,所以不需要担心重复匹配对分析造成干扰。
由于每个归档日志文件内部是有序的,而且版本号越大日志记录内容越老,所以这里用 ls 和 tac 按版本号倒序排列文件,然后将文件进行拼接。这里对普通文本文件没有排序,进一步优化则是(有点稍显复杂了):
ls --sort=version /var/log/dpkg.log.*.gz | tac | xargs zcat |
grep -E ' installed' - $(ls -t /var/log/dpkg.log* | cat | grep -v '\.gz' | tac)
查看 systemd 异常
先检查 systemd status 是否报告异常。如果有单元是 failed 状态,就用 systemctl --state=failed 来列举异常单元。
有一次我是找到 NetworkManager-wait-online.service 状态为 failed:
xx@yy-Rack-Server:~$ systemctl --state=failed
UNIT LOAD ACTIVE SUB DESCRIPTION
● NetworkManager-wait-online.service loaded failed failed Network Manager Wait Online
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
1 loaded units listed.
有些日志文件需要权限才能查看,所以我加了 sudo(不加的话能看到警告,而且信息要少一点):
xx@yy-Rack-Server:~$ sudo systemctl status NetworkManager-wait-online
× NetworkManager-wait-online.service - Network Manager Wait Online
Loaded: loaded (/lib/systemd/system/NetworkManager-wait-online.service; enabled; vendor preset: enabled)
Active: failed (Result: exit-code) since Fri 2025-04-18 15:05:03 CST; 19min ago
Docs: man:nm-online(1)
Process: 3288 ExecStart=/usr/bin/nm-online -s -q (code=exited, status=1/FAILURE)
Main PID: 3288 (code=exited, status=1/FAILURE)
CPU: 49ms
4月 18 15:04:03 yy-Rack-Server systemd[1]: Starting Network Manager Wait Online...
4月 18 15:05:03 yy-Rack-Server systemd[1]: NetworkManager-wait-online.service: Main process exited, code=exited, status=1/FAILURE
4月 18 15:05:03 yy-Rack-Server systemd[1]: NetworkManager-wait-online.service: Failed with result 'exit-code'.
4月 18 15:05:03 yy-Rack-Server systemd[1]: Failed to start Network Manager Wait Online.
重启这个服务就好了:
sudo systemctl restart NetworkManager-wait-online
这个服务到底是什么?不影响上网,只是影响 systemd 的一个显示。好像只是用来测试网络,有些模块会依赖它,如果它失败这些模块将无法启动,从而系统进入 degraded 状态。
检查哪些模块依赖了它(很长一串列表,所以用了 head 减少输出):
➜ ~ systemctl list-dependencies NetworkManager-wait-online.service | head 34672ms
NetworkManager-wait-online.service
● ├─NetworkManager.service
● ├─system.slice
● └─sysinit.target
● ├─apparmor.service
● ├─dev-hugepages.mount
● ├─dev-mqueue.mount
● ├─keyboard-setup.service
● ├─kmod-static-nodes.service
● ├─plymouth-read-write.service
查找进程
ps -ef
ps aux
# 需要自己指定格式的时候就不能用 u,因为 u 也是一种格式指定(会增加资源用量、用户、启动时间等),会冲突
ps axf -o user,pgid,ppid,pid,tid,cmd
ps -ef 显示的内容和 ps ef 不同,比 ps aux 少一些。
安装 sysstat 获取 CPU/ 磁盘 / 网络统计日志
防患于未然!下次服务器出问题重启之后,还能查看以前的资源使用日志。
安装 sysstat 包:
sudo apt install sysstat
用 root 权限修改 /etc/default/sysstat 中的 ENABLED 选项为 true。
然后启动 sysstat 服务(如果还没修改 /etc/default/sysstat,得修改然后重新启动服务):
sudo systemctl start sysstat
sudo systemctl enable sysstat
用 sar -u 来验证是否成功开启资源监控日志,如果成功能看到记录,否则会输出错误消息。
使用 sar:
- 用
-f选项指定具体的日志(在 /var/log/sysstat 中的 saDD 文件中,其中 DD 为数字),否则默认使用最新日志。 - 用
sar -u指定 CPU 使用情况。 - 用
sar -n DEV检查网络(后缀真的是 DEV,这个不是占位符)。 - 用
sar -d检查块设备传输。 - 用
sar -rh以人类可读形式显示内存占用。
问题:隔了很久都没有等到监控日志,这是为什么?
这是因为我当时不知道要修改 /etc/default/sysstat 配置。
检查发现 sysstat 在 cron 中配置了任务:
➜ ~ cat /etc/cron.d/sysstat
# The first element of the path is a directory where the debian-sa1
# script is located
PATH=/usr/lib/sysstat:/usr/sbin:/usr/sbin:/usr/bin:/sbin:/bin
# Activity reports every 10 minutes everyday
5-55/10 * * * * root command -v debian-sa1 > /dev/null && debian-sa1 1 1
# Additional run at 23:59 to rotate the statistics file
59 23 * * * root command -v debian-sa1 > /dev/null && debian-sa1 60 2
脚本 debian-sa1 内容如下:
➜ ~ cat /usr/lib/sysstat/debian-sa1 5116ms
#!/bin/sh
# vim:ts=2:et
# Debian sa1 helper which is run from cron.d job, not to needlessly
# fill logs (see Bug#499461).
set -e
# Skip in favour of systemd timer
[ ! -d /run/systemd/system ] || exit 0
# Our configuration file
DEFAULT=/etc/default/sysstat
# Default setting, overridden in the above file
ENABLED=false
# Read defaults file
[ ! -r "$DEFAULT" ] || . "$DEFAULT"
[ "$ENABLED" = "true" ] || exit 0
exec /usr/lib/sysstat/sa1 "$@"
也就是说它会根据 /etc/default/sysstat 的配置来确定是否真正运行 /usr/lib/sysstat/sa1,默认是不运行的,还要先用 root 权限改成 true:
➜ ~ cat /etc/default/sysstat
#
# Default settings for /etc/init.d/sysstat, /etc/cron.d/sysstat
# and /etc/cron.daily/sysstat files
#
# Should sadc collect system activity informations? Valid values
# are "true" and "false". Please do not put other values, they
# will be overwritten by debconf!
ENABLED="false"
而 /usr/lib/sysstat/sa1 也是脚本,处理好逻辑之后会调用 /usr/lib/sysstat/sadc 这个二进制文件。
然后还要重启一下 sysstat 服务!
sudo systemctl restart sysstat