实验室服务器 ssh 无法连接
事情由来
实验室在今年初安装了两台新的服务器,IP 最后一个段分别为 149 和 150,后文将用这两个数字来指代服务器。据说 149 服务器网络出现故障。
检查网络配置(非原因,可以跳过)
用 journalctl 看日志说 dhcp4 失败。包失败的,服务器都是静态 ip,没有配置 dhcp 服务器。为什么明明是静态 ip 却要尝试使用 dhcp 服务器呢?
禁用异常的网络接口
考虑到安装的是桌面版,起作用的是 NetworkManager。
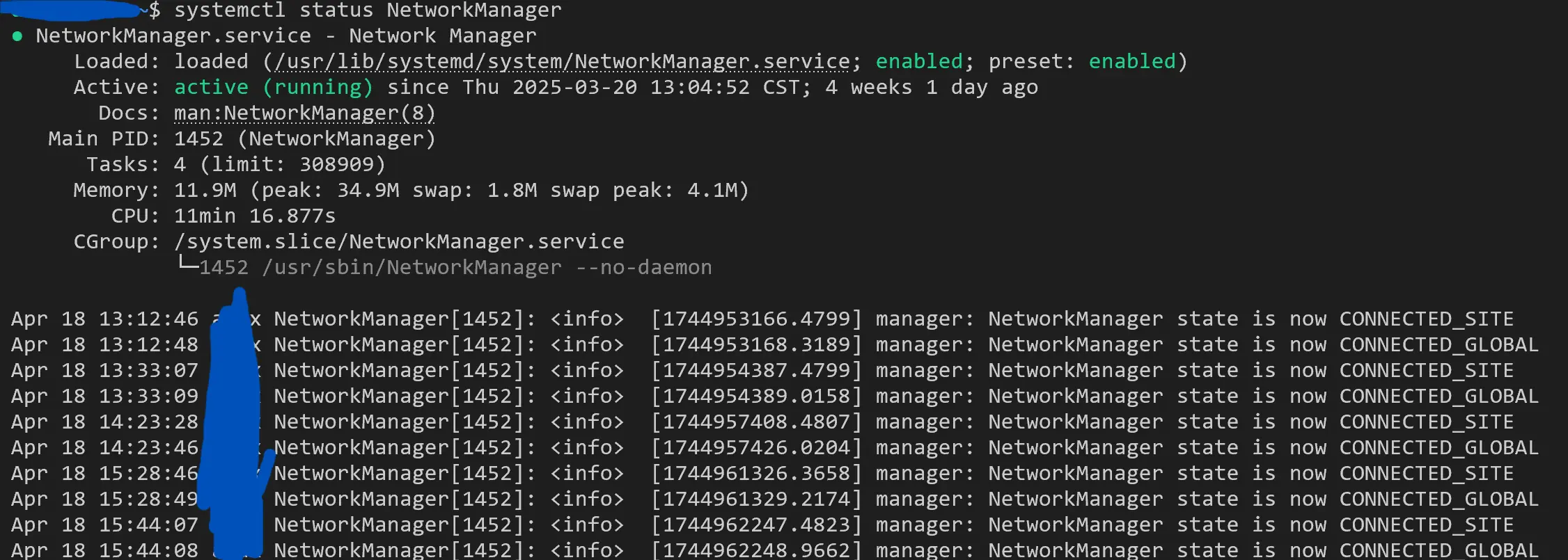
再检查一下,systemd-networkd 果然不活跃,确实应该是去检查 NetworkManager。

检查一下 NetworkManager 的配置:
xx@yy-Rack-Server:~$ NetworkManager --print-config
# NetworkManager configuration: /etc/NetworkManager/NetworkManager.conf (lib: 10-dns-resolved.conf, 10-globally-managed-devices.conf, 20-connectivity-ubuntu.conf, no-mac-addr-change.conf) (etc: 10-ubuntu-fan.conf, default-wifi-powersave-on.conf)
[main]
# rc-manager=
# auth-polkit=true
# dhcp=internal
# iwd-config-path=
dns=systemd-resolved
plugins=ifupdown,keyfile
configure-and-quit=no
[connectivity]
uri=http://connectivity-check.ubuntu.com./
[ifupdown]
managed=false
[keyfile]
unmanaged-devices=*,except:type:wifi,except:type:gsm,except:type:cdma,interface-name:fan-*
[logging]
# backend=journal
# audit=true
[device]
# wifi.backend=wpa_supplicant
wifi.scan-rand-mac-address=no
[device]
# wifi.backend=wpa_supplicant
wifi.scan-rand-mac-address=no
[device-31-mac-addr-change]
match-device=driver:eagle_sdio,driver:wl
wifi.scan-rand-mac-address=no
[connection]
wifi.powersave=3
# no-auto-default file "/var/lib/NetworkManager/no-auto-default.state"
这个配置 Gemini 解读的很好(尽管在 /etc/NetworkManager/system-connections/ 目录下不能找到它提到的配置文件)。系统通过 netplan 来管理网络,它使用 /etc/netplan/01-network-manager-all.yaml 配置文件,每次修改之后要用 sudo netplan apply 来重载。根据配置文件可知 netplan 使用 NetworkManager 来管理网络:
network:
version: 2
renderer: NetworkManager
附:我对配置文件中网络管理逻辑层级的理解:
netplan -> NetworkManager -> ifupdown
-> keyfile
-> ...
根据 Gemini 的提示用 nmcli device status 列举设备状态:
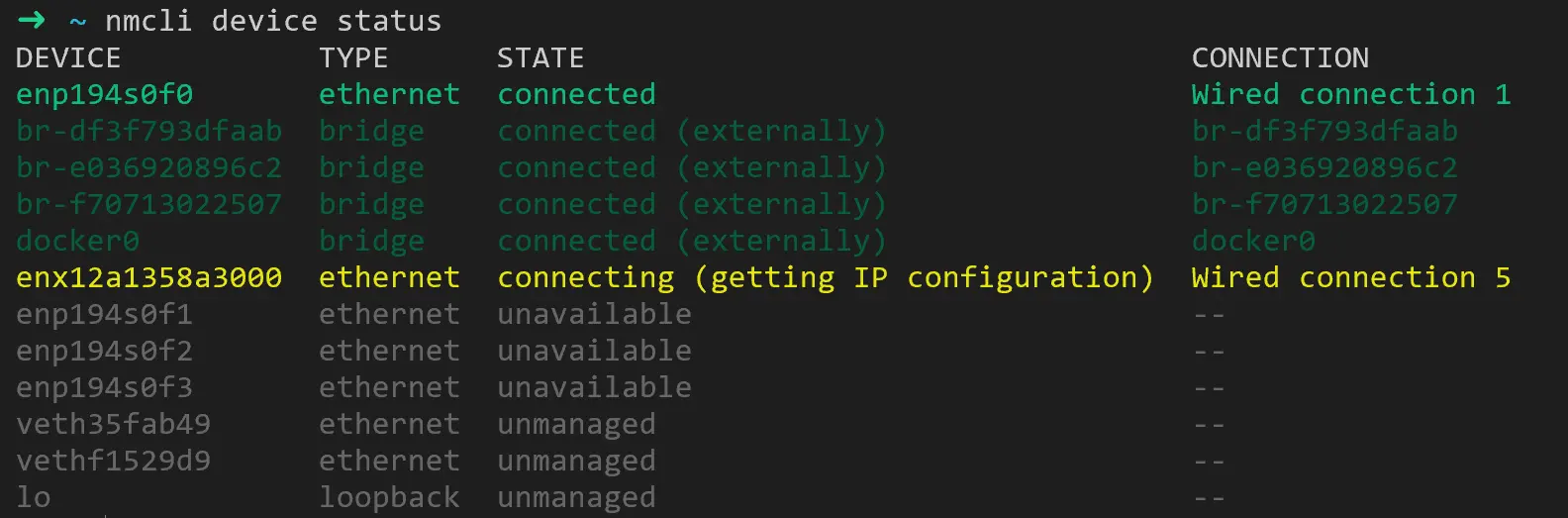
可以看到 enx12a1358a3000 这个设备始终在尝试连接,这是我们新安装的两台服务器出现的问题。估计之前在 journalctl 中频繁看到的错误也是这个接口引起的(隔一段时间会变成红色,失败一段时间之后又重试)。检查其他正常的服务器,没有总是在 connecting 状态的接口,都是要么绿色要么灰色。
另外,正常的服务器和异常的服务器的配置文件也不同。
正常(内网 ip 最后一个段是 150):

同时 NetworkManager 文件夹下面有配置:
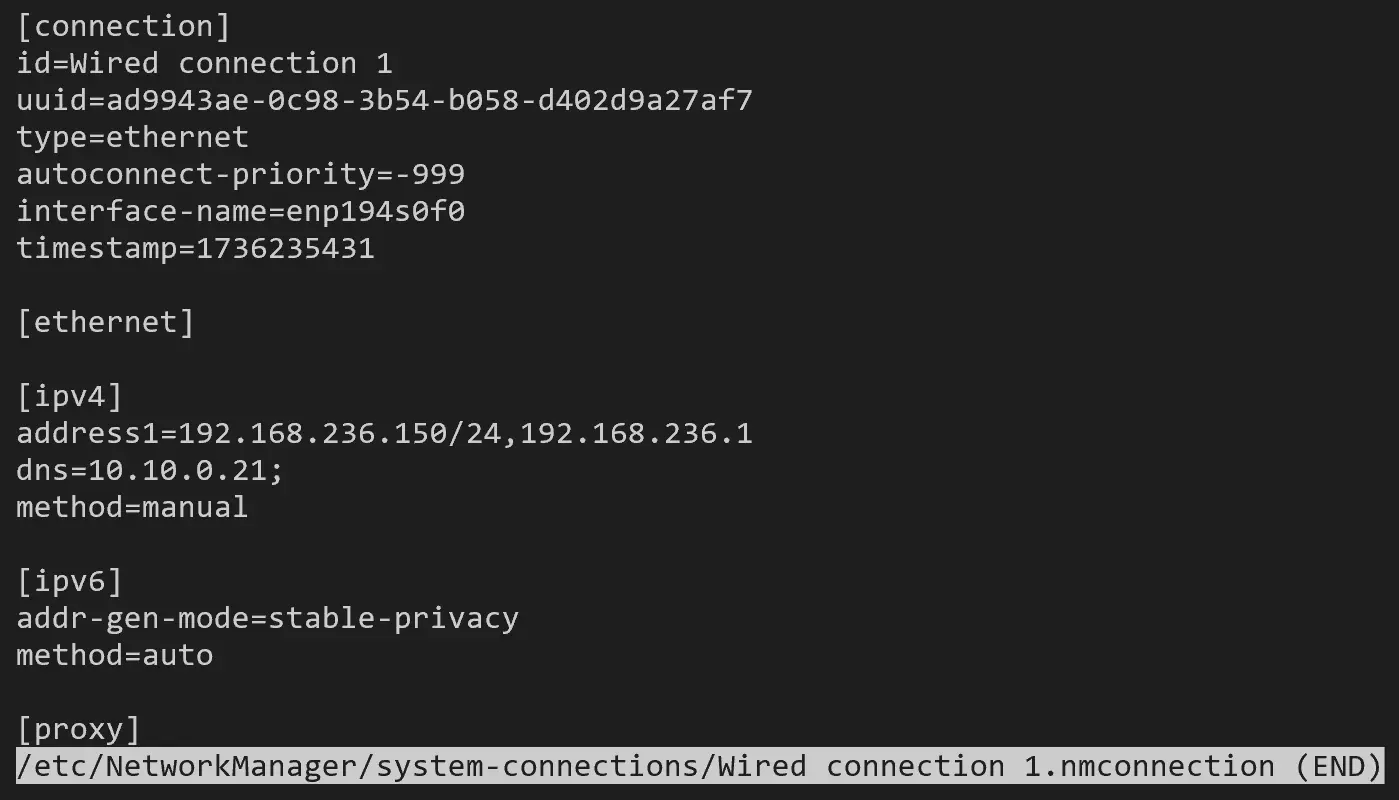
(base) ➜ ~ sudo grep '150' -ir /etc/NetworkManager/
/etc/NetworkManager/system-connections/Wired connection 1.nmconnection:address1=192.168.236.150/24,192.168.236.1
异常(内网 ip 最后一个段是 149):
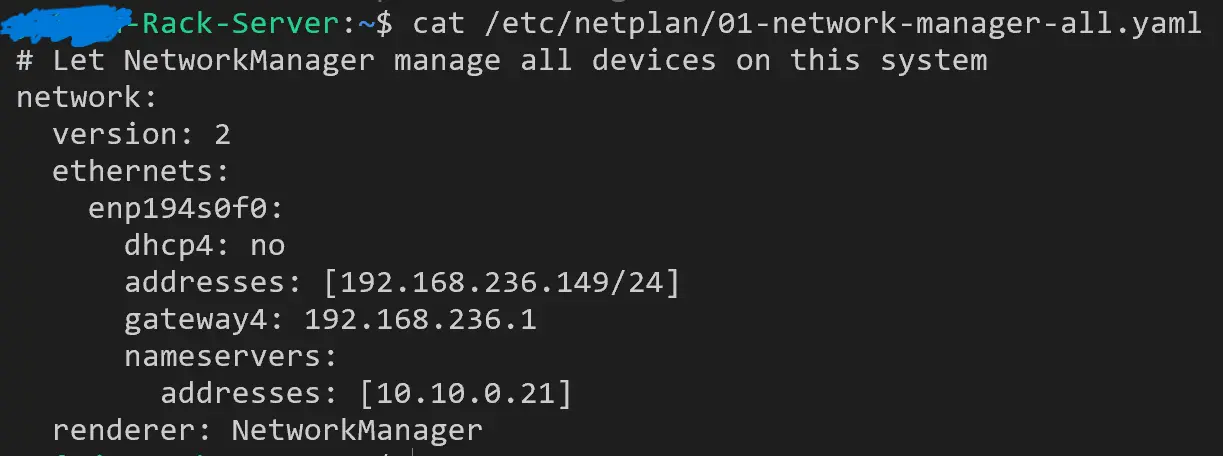
同时在 /etc/NetworkManager 中找不到配置(配置已经在 /etc/netplan/01-network-manager-all.yaml 中了)。
xx@yy-Rack-Server:~$ sudo grep '149' -ir /etc/NetworkManager/
xx@yy-Rack-Server:~$
两台服务器是一起安装的,不知道为什么 IP 配置的方法不同,一直找不到原因。猜测是因为一台服务器是通过图形化界面配置的,另一台是命令行配置的?(我们实验室服务器安装的都是图形化界面,方便去机房干预,老传统了。)
尝试了这个解决方案:在 /etc/netplan/01-network-manager-all.yaml 中禁止 nmcli device status 展示出来的异常设备的 dhcp 连接,然后 sudo netplan apply,稍等一段时间,nmcli device status 输出就正常了(出错的接口转变成 connected,检查发现有了内网地址)。
network:
version: 2
ethernets:
enx8a350fe0be23:
dhcp4: no
dhcp6: no
回顾
但是 150 服务器也有这个错误(在 journalctl 中也能看到不断获取 dhcp 地址的日志)却能正常运行,不知道是否是这个原因导致服务器异常。
服务器还有 ping 8.8.8.8 丢包的问题,经过检查发现 ping 阿里云的 dns 服务器也会出现这样的问题,而且不仅仅是出现问题的服务器有这个现象,没有出现问题的服务器也有这个现象。判断是机房网络不好,并不是造成此次 ssh 无法连接问题的原因。
非网络情况的分析
检查上上次关机以来的内核日志(因为已经被迫重启了一次):
sudo journalctl -b -1 -xe SYSLOG_IDENTIFIER=kernel

据 Gemini,分配页面缓存(用于文件 I/O)慢,可能是内存使用完了?
在 Linux kernel 源码中搜索 fill_page_cache_func 这个函数,虽然其中使用了 raw_spin_lock_irqsave 和 raw_spin_unlock_irqrestore,但我认为这不一定是卡住 CPU 的原因。__get_free_page 这个函数看起来比较可疑,也许是找空闲页面花费的时间太长了?可以参考 alloc_page 分配内存 - 知乎 这篇文章(稍微有点旧了)。
在 include/linux/gfp.h 有定义:
extern unsigned long get_free_pages_noprof(gfp_t gfp_mask, unsigned int order);
#define __get_free_pages(...) alloc_hooks(get_free_pages_noprof(__VA_ARGS__))
#define __get_free_page(gfp_mask) \
__get_free_pages((gfp_mask), 0)
绕了很多圈,最终是到了 __alloc_frozen_pages_noprof 这个函数(截至 2025/4/18),这个函数调用 get_page_from_freelist 尝试从 zonelist 中找到一个可用的页面,看起来很可能是内存不够导致的 ssh 无响应。
我们服务器的 256 核心 + 512G 好像是有点问题。很多程序启动的时候(默认)都是根据查询到的 CPU 核心数(
nproc)来确定任务量,因此可能会启动 128 个任务,每个任务都会占用大量内存。比如有同学试过编译 vllm 使用所有 CPU 核心必定导致服务器卡死。以前的服务器是 32 核心 + 256G 内存的,虽然内存小一些,但是出现这么严重的无法登录的情况反而更少。我看网络资料,对于个人用台式机,建议每个核心配备 4GB 内存,有 I/O 密集型需求可以翻倍。我们这个服务器才 2G/core。
以上为猜测。
最后
一方面是屏蔽了一个疑似有问题的接口(但是很可能不是这个问题),另外一方面是确认服务器无法连接之前很可能出现了内存不足的问题。