实验室服务器故障(续)
背景
本文是 实验室服务器 ssh 无法连接 的后续。
今天同学又告诉我发生了类似的情况,师兄已经在找人维修。
我连接上去看了服务器重启时间约 10 点。又看了几个信息:
sar监控journalctl日志- 磁盘信息
sar 监控
之前设置的 sar 监控频率是默认的,即 10 分钟采样一次。sar 怎么安装和配置可以参考
安装 sysstat 获取 CPU/ 磁盘 / 网络统计日志。
查看今天所有的资源统计(主要是晃过去看看哪些是红色):
S_COLORS=always sar -A | less -R
一些观察到的情况:
CPU(相当于 sar -u):观察到 %usr 只有几个核心在较高水平(70% 以上,有的能达到 100%),其他核心基本上是 idle。
内存(sar -r):1:50 到 4:50 之间 %commit 都在 80% 以上,之后退下来。
分页统计(相当于 sar -B):观察到 %vmeff 有红色(极大值)和蓝色(小值)。注意 sar 输出为红色并不代表不好,只是表示数值大。
%vmeff(虚拟内存效率)表示内存回收效率,计算公式为 (pgsteal / (pgscank + pgscand)) * 100,其中:
- pgsteal:每秒回收的页面数。
- pgscank:由 kswapd 守护进程扫描的页面数。
- pgscand:直接由进程扫描的页面数。
按照我的理解,%vmeff 反映回收性能,如果低也可能说明这段时间没有回收活动。在有回收活动的时候数值低则暗示回收效率低下。这些数据表明凌晨运行的程序导致了大量的页面换出。(结合 1:50 之前内存还充足,可以考虑主要是磁盘 I/O 引发的,而不是进程的内存页面?)
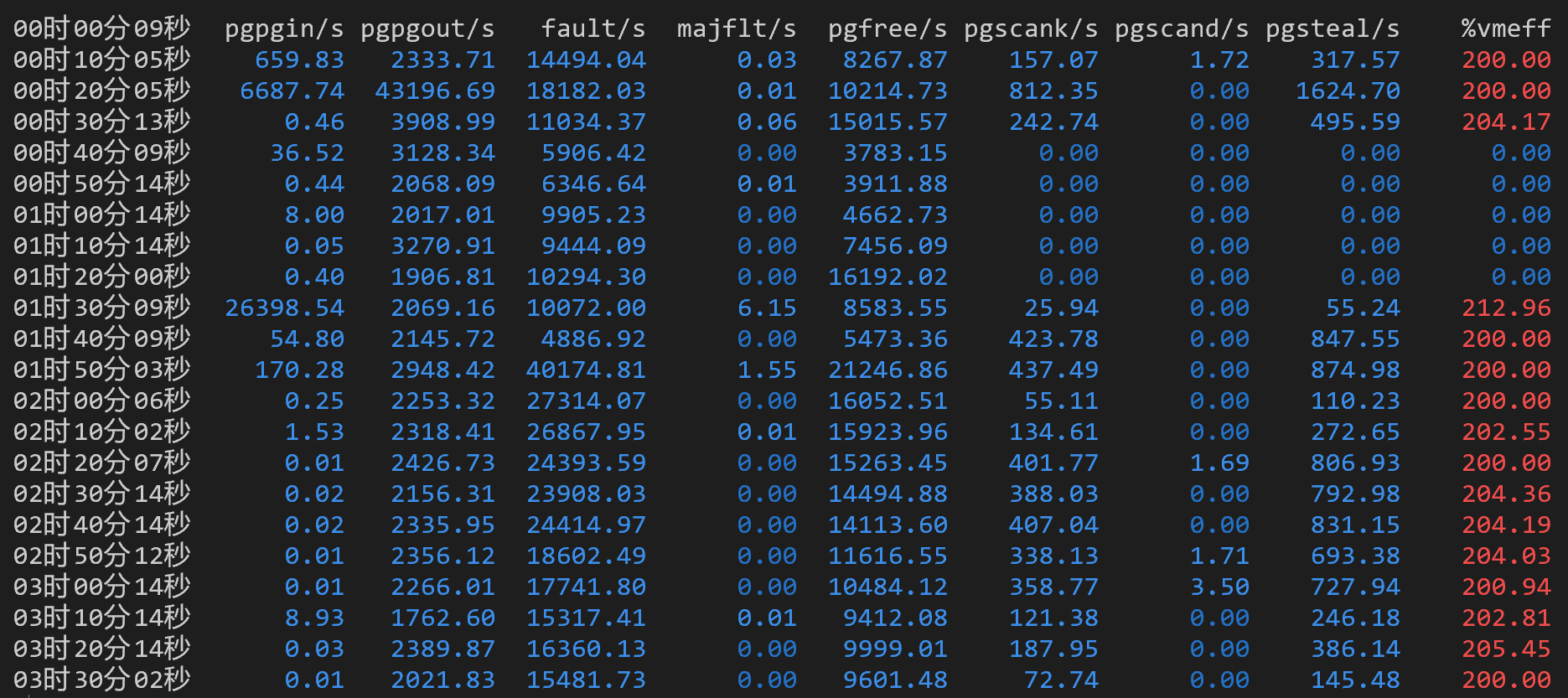
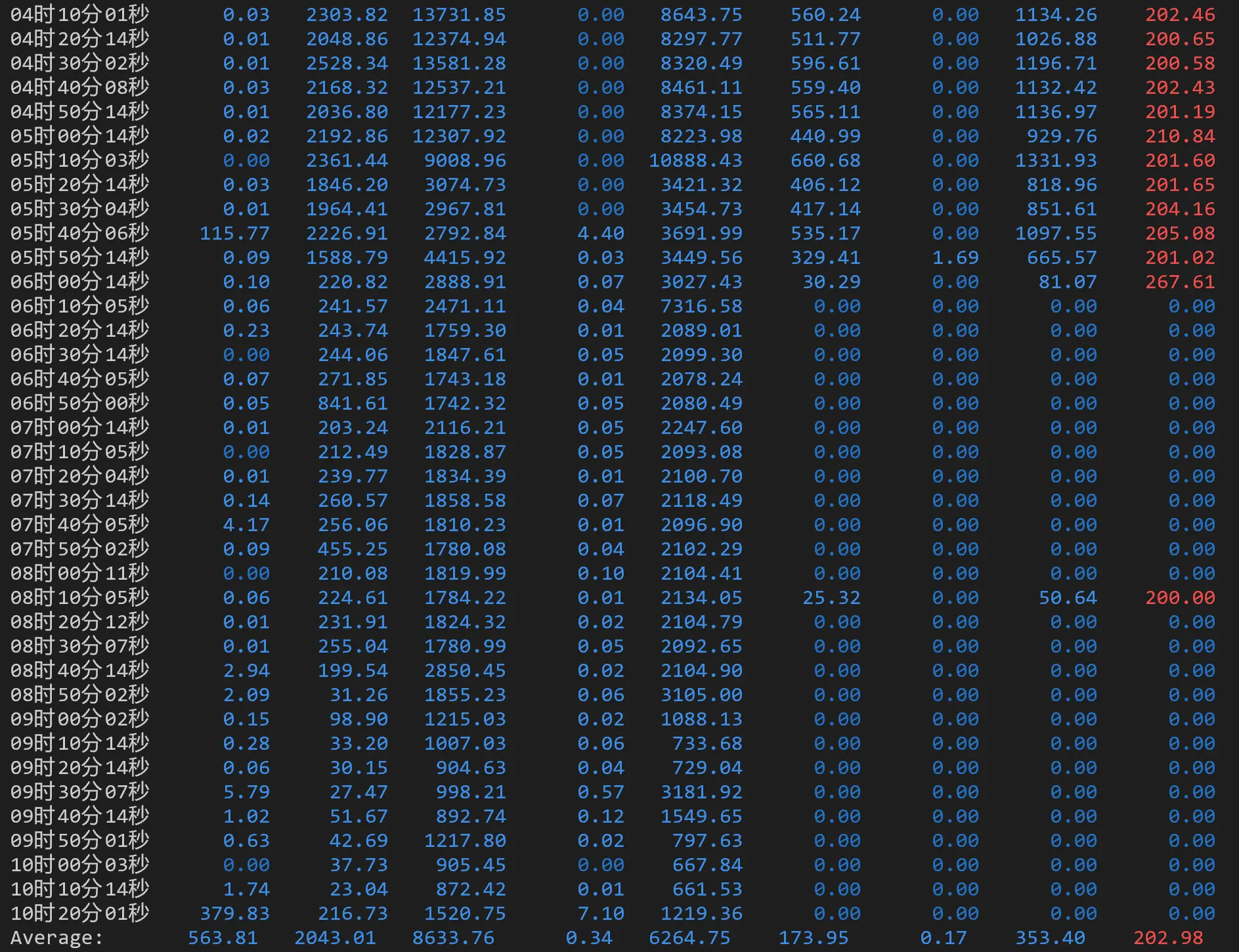
磁盘写入(sar -n DEV):可以看到运行的程序在大量写磁盘,在凌晨的几个小时写的非常多,而在被迫关机的这段时间写的比较少。
journalctl 日志
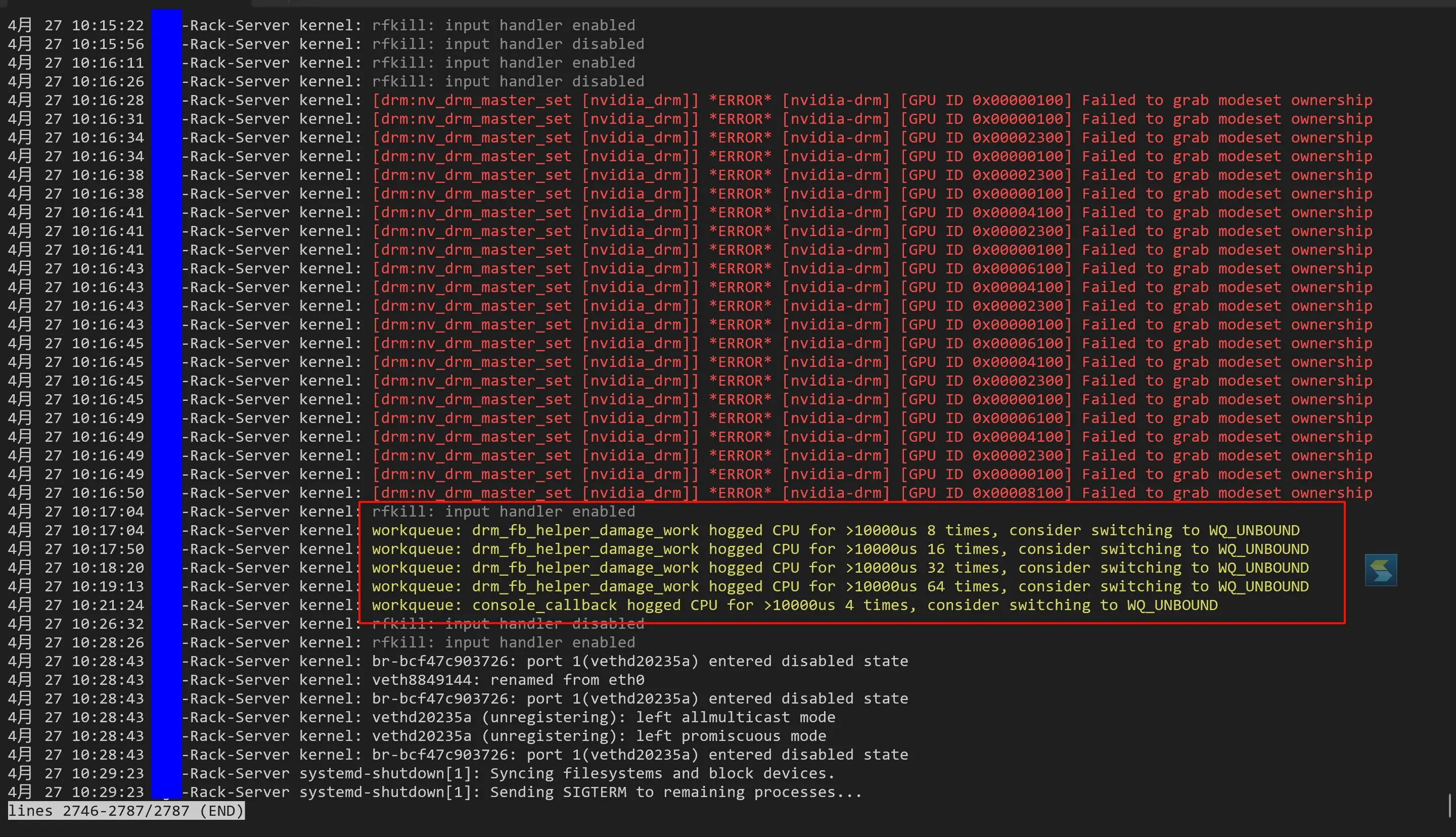
一是大段的 GPU 设备查询报错,不知道是否良性,二是和上一次一样有某些内核功能卡住了 CPU 太久。都在下图。
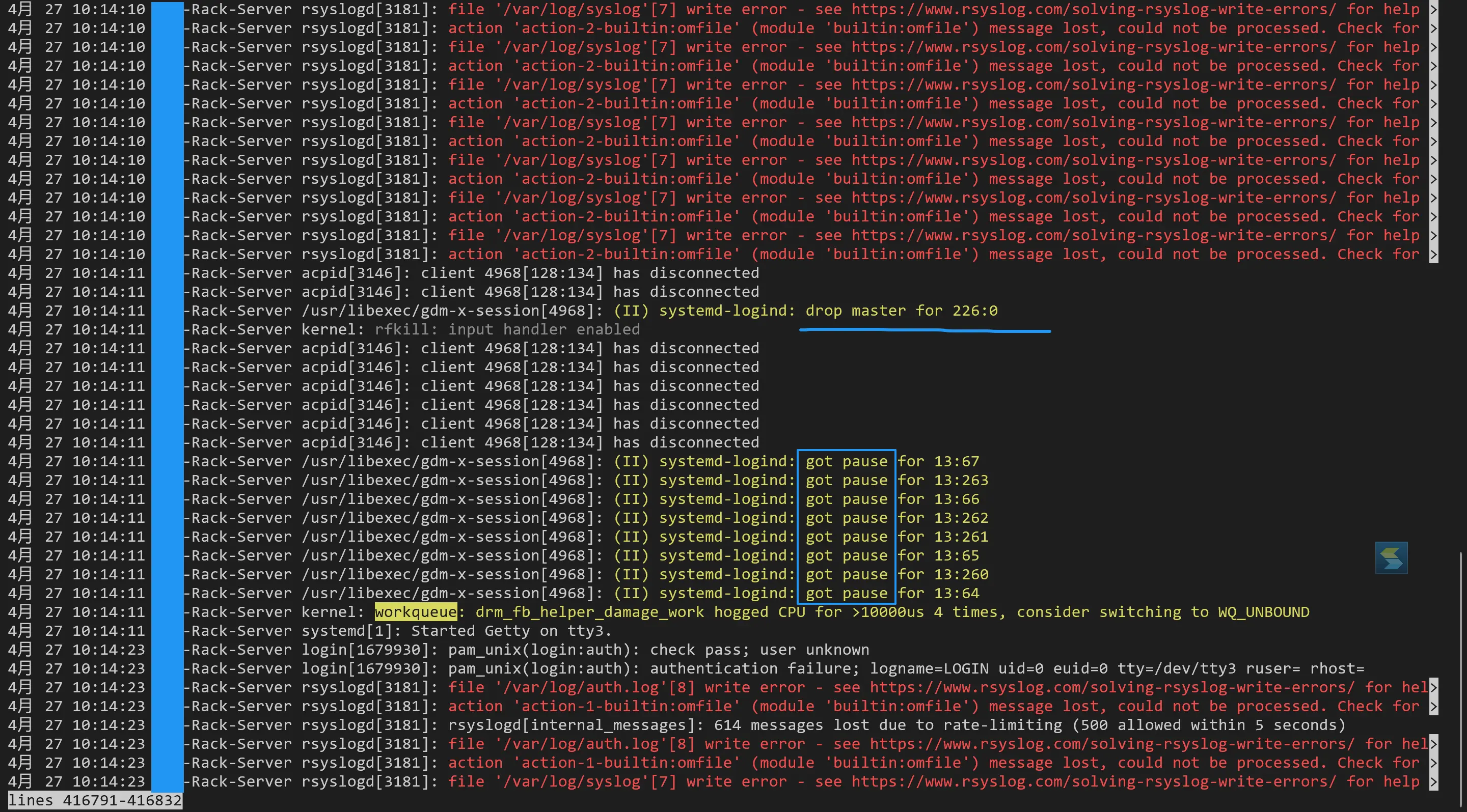
三是 sar 日志写不进去,还伴随着其他警告。后面的 major:minor 是设备号,可能表示显卡。
磁盘
想要开启 tmux,说无法创建文件。
xx@yy-Rack-Server:~$ tmux
couldn't create directory /tmp/tmux-1001 (No space left on device)
磁盘满了。
$ df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 51G 4.1M 51G 1% /run
/dev/nvme0n1p2 3.5T 3.3T 0 100% /
tmpfs 252G 0 252G 0% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
efivarfs 128K 16K 108K 13% /sys/firmware/efi/efivars
/dev/nvme0n1p1 511M 6.1M 505M 2% /boot/efi
tmpfs 51G 184K 51G 1% /run/user/1007
tmpfs 51G 68K 51G 1% /run/user/1013
tmpfs 51G 68K 51G 1% /run/user/1001
tmpfs 51G 68K 51G 1% /run/user/1012
结论
运行的程序是 I/O 密集型的,可能是磁盘写满导致很多功能异常?