Python 多进程脚本的常见问题
占用过多内存
TL;DR:大多是具体脚本的问题,不好处理。有的是没有及时 gc,有的是把所有数据全部载入内存之后(假设了内存足够大)才开始处理。
我是遇到了这样一个问题: megatron-lm huggingface 教程运行时资源占用大、有僵尸(2025/4/22 文章还在修改中,尚未公开)。

o4-mini 建议我调整启动方式:multiprocessing — Process-based parallelism — Python 3.13.3 documentation
| 方法 | 描述 | 特征 |
|---|---|---|
| spawn | 创建新的解释器并运行,干净但慢,是 Windows、macOS 的默认方法。 | 大量 python -c from multiprocessing.spawn import spawn_main; 进程 |
| fork | 直接 fork。除了 macOS 之外的 POSIX 的默认方法,Python 3.14 之后默认方法改成 forkserver。 | 大量命令参数(cmd)和启动命令相同的进程,例子 python tools/preprocess_data.py --input ... |
| forkserver | 首次用 forkserver 方法创建进程会启动一个单线程(除非 import 的库导致了多线程)的 server,每次调用 os.fork() 都是干净的,不会有冗余线程。 | 大量 python -c from multiprocessing.forkserver import ... 进程 |
但是我觉得调整启动方式对内存占用的影响很难观察到,但 fork 比 forkserver 的速度快一点(可能是我的用例如此)。
相关:Excessive memory buildup when merging text datasets in Megatron core · Issue #12993 · NVIDIA/NeMo,不过我操作之后还是会占用大量内存。后来发现其实是这个脚本把所有数据全部放在内存中,然后一次性处理,所以是脚本本身没有考虑到内存不够的场景。
产生大量睡眠进程
使用 forkserver 很容易出现大量 S 进程(睡眠状态),占用大量内存。可以使用以下方法来杀:
sudo kill -9 $(ps aux | grep multiprocessing.forkserver | grep -v grep | awk '{print $2}' |less)
这也许是快速连续按下 ctrl+c,导致程序没有来得及做清理工作导致的?
产生大量僵尸
相关资料:
- PyTorch causes zombie processes on multi-GPU system - PyTorch Forums
- PyTorch doesn’t free GPU’s memory of it gets aborted due to out-of-memory error - PyTorch Forums
快速检查:ps aux | grep Z。示例:
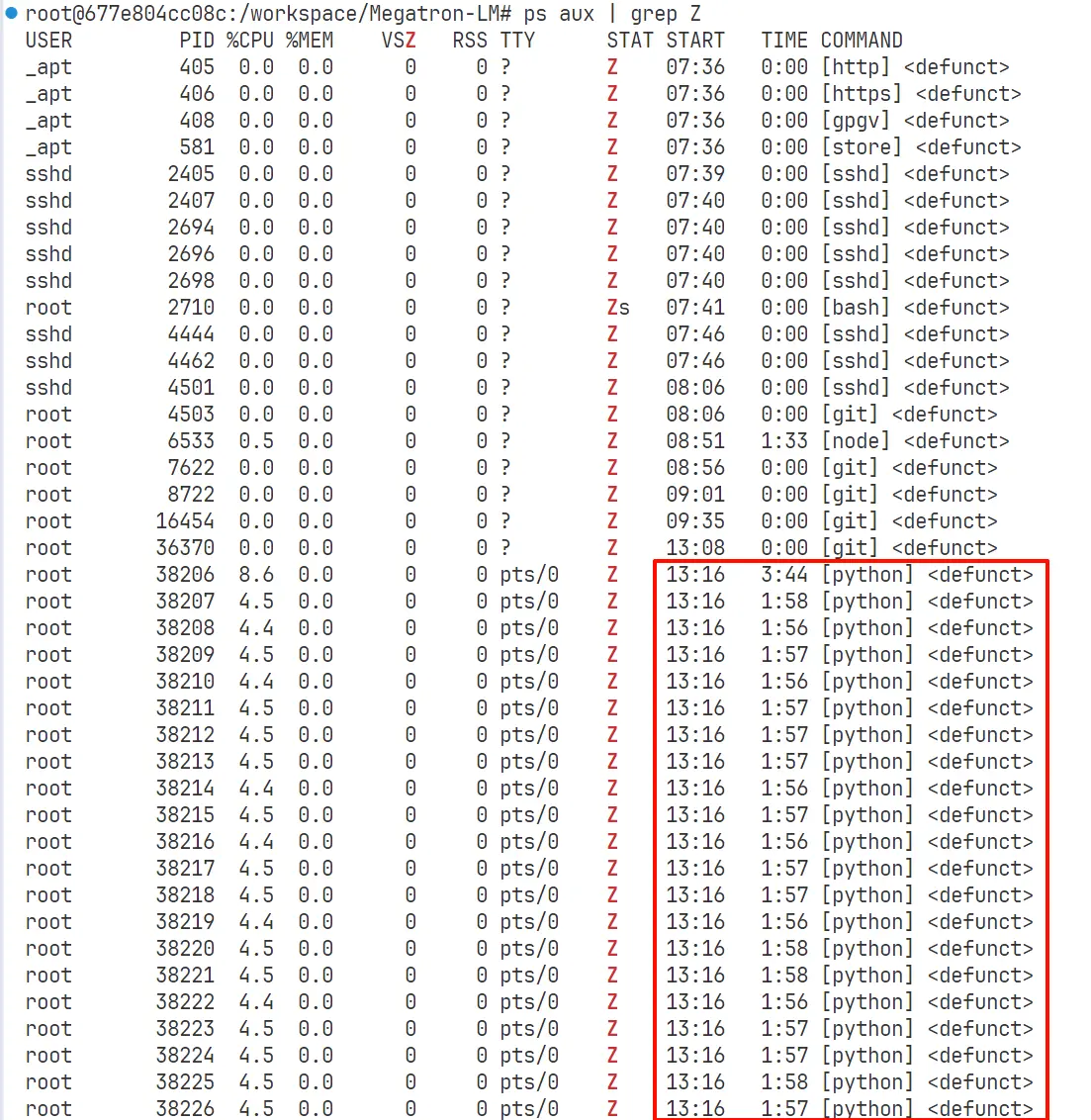
如果要在脚本中查找僵尸,需要严格检查第 8 个域(如果 ps 选项更改,这个位置也可能会变化),以免出现 USER 或者 COMMAND 出现 Z 字母造成误伤。
ps aux | awk 'match($8, ".*Z.*")'
如果还想要找到具体的 pid:
ps aux | awk 'match($8, ".*Z.*")' | awk '{print $2}'
僵尸怎么杀?杀父进程,让 init 来收养并 reap。
但是,我使用的是容器环境,它的 init 不具备处理 SIGCHLD 信号的功能!
(base) ➜ ~ ps ax --sort=ppid -o user,pid,ppid,%cpu,%mem,stat,start,time,command |awk 'match($6, ".*Z.*")' |awk '{print $3}'|sort -u
2260730
(base) ➜ ~ sudo kill -SIGCHLD 2260730
(base) ➜ ~ ps ax --sort=ppid -o user,pid,ppid,%cpu,%mem,stat,start,time,command |awk 'match($6, ".*Z.*")' |awk '{print $3}'|sort -u
2260730
(base) ➜ ~ # kill -SIGCHLD 没有任何效果!
这个确实是我启动 docker 容器时的失误😅。我是想要创建一个持久的容器,然后 docker exec 进入执行具体任务。应该这样启动容器:
docker run --init image_name tail -f /dev/null

如果已经出现了大量僵尸,但不想销毁容器,可以重启:
docker restart container_name