读 On Java 8
Chapter 00-11
Java 对象构造顺序:1、基类 2、所有域 3、初始化块 4、自身的构造函数
jshell> a = new Foo()
Value initialization
Initialization block
Constructor
为接口提供默认实现:

逆变、协变、不变的关系:

在 Java 的子类中 override 了父类的方法,返回一个协变类型也是可以的。比如基类规定的是返回 Object,重写的方法里面是可以写返回任意对象的。
接口中的属性自动是 final 和 static 的。比如:S 自动就是 final 和 static 的,因为它是在接口中定义的。也正因为这样,接口曾用来方便地定义一组常量,不过 Java5 之后可以用 enum 替代 interface 实现部分功能了。

这个特性还能用来做测试。比如我根本不想给每个常量域提供冗长的 private static 前缀:(main 仍然要加 static,否则就不能被识别成类中可以运行的 main 方法,而是成为一个接口中的方法)
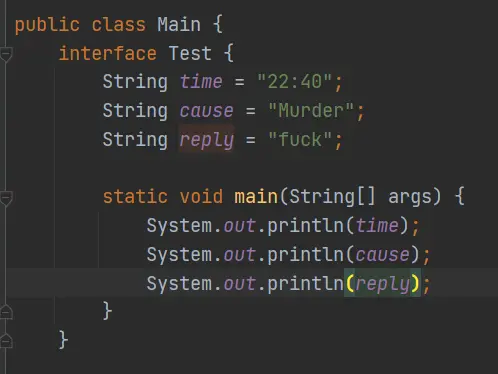
可惜的是,如果在接口外使用这些常量,就需要把接口名也加上了,这样用起来就长了好多。另外一种思路是:其实在 main 中烦人的是只能使用静态的域,权限则无关紧要。可以把数据作为实例的域。然后申请一个对象在 main 中操作。缺点是在对象实例中放常量总觉得十分奇怪。
在 Class 中套 Test interface 的另外一个好处是:可以只保留一个主文件 Main.java,不需要修改文件本身的名称。
Read MANIFEST from .jar file:
unzip -q -c $(JARFILE) META-INF/MANIFEST.MF
Chapter 12-14
链表 LinkedList
LinkedList 也像 ArrayList 一样实现了基本的 List 接口,但它在 List 中间执行插入和删除操作时比 ArrayList 更高效。然而,它在随机访问操作效率方面却要逊色一些。
LinkedList 还添加了一些方法,使其可以被用作栈、队列或双端队列(deque) 。在这些方法中,有些彼此之间可能只是名称有些差异,或者只存在些许差异,以使得这些名字在特定用法的上下文环境中更加适用(特别是在 Queue 中)。例如:
getFirst()和element()是相同的,它们都返回列表的头部(第一个元素)而并不删除它,如果 List 为空,则抛出 NoSuchElementException 异常。peek()方法与这两个方法只是稍有差异,它在列表为空时返回 null 。removeFirst()和remove()也是相同的,它们删除并返回列表的头部元素,并在列表为空时抛出 NoSuchElementException 异常。poll()稍有差异,它在列表为空时返回 null 。addFirst()在列表的开头插入一个元素。offer()与add()和addLast()相同。 它们都在列表的尾部(末尾)添加一个元素。removeLast()删除并返回列表的最后一个元素。在列表为空时抛出 NoSuchElementException 异常。
💡 记忆:其中 peek 和 poll 都是获取开头元素的,他们都不引发异常,只是返回null。更明确一点的是 peekFirst、peekLast 这样的接口,他们也都不引发异常。poll也有类似的版本。除了 peek、poll 这种简明的表达,其他的获取元素都是可能引发异常的。
LinkedList 的接口很复杂,不过 List 接口中有 get、add、remove、set 也应该够了。只是操作开头或者末尾元素时要明确给出 index。
ArrayList 就没有上面这些丰富的函数。需要自己用基本函数来构造。
ArrayDeque<> 是实现了 Deque 的一个泛型类。因为 Stack 的设计太糟糕了,因此一般用 ArrayDeque 代替。也可以用 LinkedList 来作为 Deque 的底层,但一般来说 ArrayDeque 性能更好。
要使用 for (String s : l) 语法,必须实现 Iterable<String> 接口。
方法引用
obj::method或ClassName::method、lambda 表达式必须转换成一个接口才能调用。- 如果要引用一个不绑定对象的非静态方法,提供的接口必须多一个对象参数(否则不能转换成功),然后调用时提供要临时绑定的对象。
- 构造函数也能引用,引用方法是
Dog::new(以类名 Dog 为例子),构造函数可能有多个重载,但是根据明确指定的接口就能绑定到对应的一个。 - Lambda 可以没有限制地引用实例变量和静态变量。但 局部变量必须显式声明为 final,或事实上是 final。
Java PrintStream 中,printf 占位符 %n 表示输出换行,且是根据不同平台换行符号的不同而换行的。而 \n 则是没有考虑到平台。
柯里化意为:将一个多参数的函数,转换为一系列单参数函数。
// 柯里化的函数:
Function<String, Function<String, String>> sum = a -> b -> a + b; // [1]
Function<String, String> hi = sum.apply("Hi "); // [2]
System.out.println(hi.apply("Ho"));
输出结果为 Hi Ho。
流
好奇怪的写法:

Optional、流、函数式编程是紧紧结合在一起的。集合类和数组可以很方便地生成流。还能用 iterate 方法来生成流,以解决数据在内存中装不下,或者不能容忍延迟的情况。
在 Java 集合中放入 null 会和集合方法的返回值混淆。如果一个集合的对象可以为空,可以用Collection<Optional<Dog>>来表示。(仍然假定存储 Dog 类对象)
Optional 对性能有影响。它可以处理函数式编程中可能断链的问题。
Chapter 15:异常
可以同时捕获多重异常:
// exceptions/MultiCatch.java
public class MultiCatch {
void x() throws Except1, Except2, Except3, Except4 {}
void process() {}
void f() {
try {
x();
} catch(Except1 | Except2 | Except3 | Except4 e) {
process();
}
}
}
可以在接口上说明好会抛出响应的异常。即便可能不会真正抛出,也要求使用该接口时按照异常说明来操作。这样可以提前为接口抢注异常类型,减少后续开发过程中的变动。比如 StringWriter 中的 close 方法并不会抛出异常。
e.printStackTrace()默认打印在标准错误流中。可以传入参数使它打印在标准输出流中。
如果只是把当前异常对象重新抛出,那么 printStackTrace() 方法显示的将是原来异常抛出点的调用栈信息,而并非重新抛出点的信息。要想更新这个信息,可以调用 fillInStackTrace() 方法,这将返回一个 Throwable对象(所以需要进行类型转换防止下面 catch 不到,因为之前就是一个 Exception,所以返回的对象其实也是一个 Exception,只是因为接口原因返回的是 Throwable),它是通过把当前调用栈信息填入原来那个异常对象而建立的,就像这样:
public static void h() throws Exception {
try {
f();
} catch(Exception e) {
System.out.println("Inside h(), e.printStackTrace()");
e.printStackTrace(System.out);
throw (Exception)e.fillInStackTrace();
}
}
这个更新信息指的是把原来异常中保存的栈信息替换为当前的栈信息。
异常链
dfe.initCause(new NullPointerException());
很多异常构造的时候不接受 cause 作为参数(尽管这非常方便),就需要使用 Throwable 的 initCause 来记录信息。
在 return 中使用 finally
如果 return 语句处在 try 块中,那么 try 块后面的 finally 也是会执行的。适合多路径返回时的清理工作。是 goto 的有效替代。
💡 但是如果在一个异常还没处理时抛出另外一个异常(比如在 finally 中),异常就会被替代,原有异常信息丢失。
子类重写父类方法可以少抛异常(如果真的不需要抛甚至不用声明),不能多抛出其他种类的异常。但构造函数必须包含父类的异常,只能多不能少,是个特例。
try-with-resources
打开和关闭流都可能发生 IOException,如果分开处理,则要在打开文件时,外部有一个 try-catch,打开文件后又要一个 try-finally 保证文件正常 close(和之前的 try-catch 就组成了 try-catch-finally),在 close 的子过程又需要包围在 try-catch 中处理 IOException。所以结果是:
- try
- open()
- catch: IOException
- finally
- try
- close()
- catch: IOException
- try
非常丑。
而 try-with-resources 可以自动释放打开的文件。省去了 finally 的编写,同时也不用再处理 close 时候的 IOException。
附录:IO 流
Java 没有 scanf,或许是不能对基本数据类型取地址?
Reader 和 Writer
在 Java1.1 中提出。以前的 InputStream 和 OutputStream 主要对字节操作(DataInputStream 可以像 Scanner 那样读一个基本类型的数据)。Reader 和 Writer 则加入了国际化,以实现面向字符操作。通过InputStreamReader和OutputStreamWriter可以方便地把原有的流转换成 Reader 和 Writer。
而后,如果有 Reader 和 Writer 则优先使用,除非需要操作字节(这个时候使用DataInputStream),减少直接使用流。
一般想要缓存(Buffered)的话在文件前面缓存。因为 PrintWriter 可能还会设置是否要自动 flush。
PrintWriter out = new PrintWriter(new BufferedWriter(new FileWriter(file)));
但是现在 Java 的 PrintWriter 有了新的构造器,打开文件写的时候不需要我们装饰多层了。
RandomAccessFile 有点像 C 语言的 FILE *:
RandomAccessFile rf = new RandomAccessFile(file, "r")
Chapter 17 Files + 附录:NIO
Paths.get 有点像 js 中的 path.join。
即使路径以 .java 结尾,使用 Path 的 endsWith(".java") 方法也会返回 false,endsWith 适用的是 basename,或者任意目录层级下的完整相对路径,而不是简单的字符串后缀比较。
Path 虽然是 nio 的内容,但是本身只是路径(即它只是字符串的封装,不能结合文件系统实际情况处理),查看文件属性时还是要转成 File。为了避免这个问题,java.nio.file 包中提供了一个 Files 工具类,用来检查 Path 的情况。这种 Path 和 Files 工具相结合的方式比原来的 File 类要直观很多。
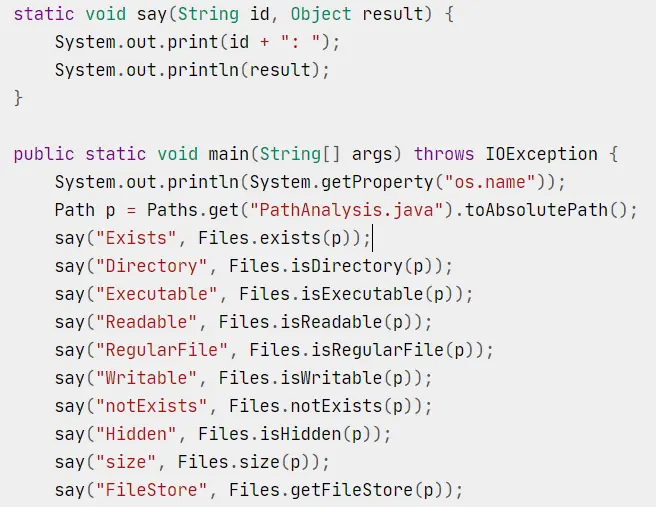
使用baseAbsolutePath.relativize(anotherAbsolutePath)来获取相对于baseAbsolutePath的相对路径。
💡 relativize 是通过计算两个绝对路径,获得一个相对路径。resolve 是通过一个相对路径作为参数,拼接两条路径(Paths.get 只接受字符串作为参数,因此 Path 的 resolve 方法依然是有必要的)。resolveSibling 则能够在当前的路径下去寻找,相当于相对路径前自动有一个 “../"(这里/即便是在 Windows 下也能够被正常识别)。
FileSystem
可以对 Path 设置路径监听,监听该目录(不递归)下的文件的修改、创建和删除操作。
可以创建 PathMatcher 来匹配文件名:
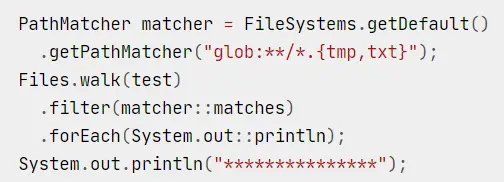
其中**表示可以递归,glob:表示这是 unix 路径通配方式,而不是 regex。
这里流就显得非常好用了。filter里面还能使用Files提供的一些谓词来过滤。Files.lines能够获得一个路径所指文件的流。按照行来划分。想要排序好则使用forEachOrdered。
如果只是想要往文件当中写内容,使用PrintWriter就好,它是自动缓存的,因此相比于没有缓存的 OutputStream 有性能提升。
💡 通过从 OutputStream 中获取 Channel 来写字节。而 Writer 则通常不需要 OutputStream 这一层就能从其他接口获得。
ByteBuffer 只能写字符数组,或 wrap 一个字符数组。使用 buff.asCharBuffer()可以往里面写字符串(应该支持所有的 CharSequence),会自动编码好。
还能往里面写所有的基本数据类型:
// 保存和读取 int:
bb.asIntBuffer().put(99471142);
System.out.println(bb.getInt());
bb.rewind();
这样一来:DataInputStream 和 DataOutStream 都可以不使用了。从而解决了 Writer 和 Reader 没有解决的问题。
可以使用 bb.order(ByteOrder.BIG_ENDIAN);来调整转换成其他基本数据类型 Buffer 视图时的大小端顺序,以写出平台无关的代码。

mark 在 reset 的时候很有用。rewind 则是抛弃 mark,回到 0。flip 则是重设 limit 为当前位置,然后回到 0,一般用于写后读。
Buffer 创建方式都是通过静态方法的,有 wrap 和 allocate。其中非 ByteBuffer 如果使用 wrap 是仍然会在底层申请空间创建 ByteBuffer 作为支持的(有数据复制)。只有 ByteBuffer 能够直接无额外开销包裹一个 byte[]。
内存映射文件

能够抽象一个在内存中装不下的文件的操作。内存映射文件初始化的代价比流要大,但是性能提升非常可观。就算是已经重写过的 Writer 和 Reader 也远远落后于内存映射文件。
文件锁定
通过调用 FileChannel 上的 tryLock() 或 lock(),可以获得整个文件的 FileLock。(SocketChannel、DatagramChannel 和 ServerSocketChannel 不需要锁定,因为它们本质上是单进程实体;通常不会在两个进程之间共享一个网络套接字)。
总结:Java 一些类的使用倾向上的变化
💡 一些不是 nio 中的:
OutputStream/InputStream 过渡到 Writer/Reader,尽量少使用前者(面向字节),而使用后者(面向字符)。
StringBuffer(同步)转为使用 StringBuilder(不保证同步)。
nio 中:
File 过渡到 Path + Files + FileSystems,用来检查文件属性、对文件整体做操作。
FileOutputStream/FileInputStream/RandomAccessFile 通过 getChannel() 可以获得对应的 FileChannel。 可以通过 FileChannel 读写文件,也能够对文件上锁,还能通过 FileChannel 获得内存映射缓冲区。可以说 FileChannel 是真正对文件的内容进行操作。
Channels 实用类可以实现 IO 流、Reader/Writer、Channel 的互转。
InputStream 是阻塞式的,如果有阻塞数据,则 nio 中的 Channel 会明显提高性能。而阻塞对输出的性能影响不大。nio 中能够明显提高性能的工具是内存映射文件。
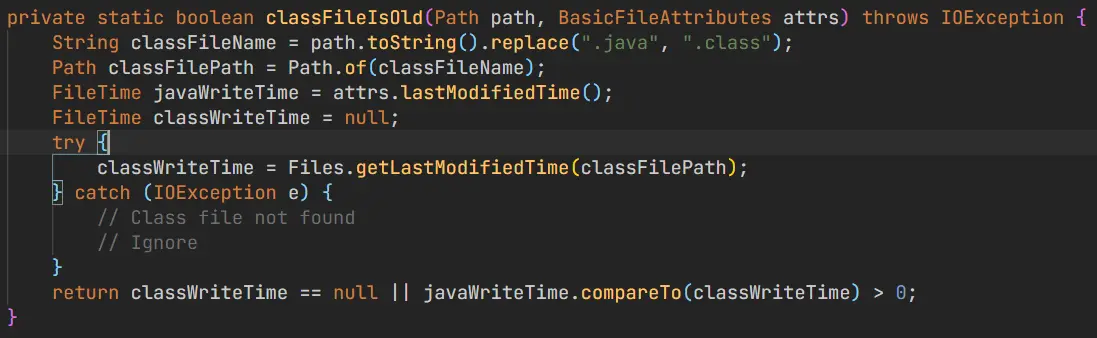
在文件遍历时提高效率
在进行一些操作之前不检查文件是否存在,而是让这些操作自己去检查,然后抛出错误。因为这些操作自己会去检查,因此如果我们也去检查一次,就会多检查了一遍。改成依赖抛出异常的方法之后,原来的执行时间(任务是去找本文件夹下所有相对于.class 更新了的.java 文件)从 0.43s 变成了 0.35~0.40s。
字符串
如果你真的想要打印对象的内存地址,应该调用 Object.toString() 方法,这才是负责此任务的方法。所以,不要使用 this,而是应该调用 super.toString() 方法。因为在对象的toString()中拼接this指针会导致toString()的循环调用。
Java 格式化打印:System.out.printf("%b\n", 0);结果是 true 。因为 0 不是布尔值,也不是空。
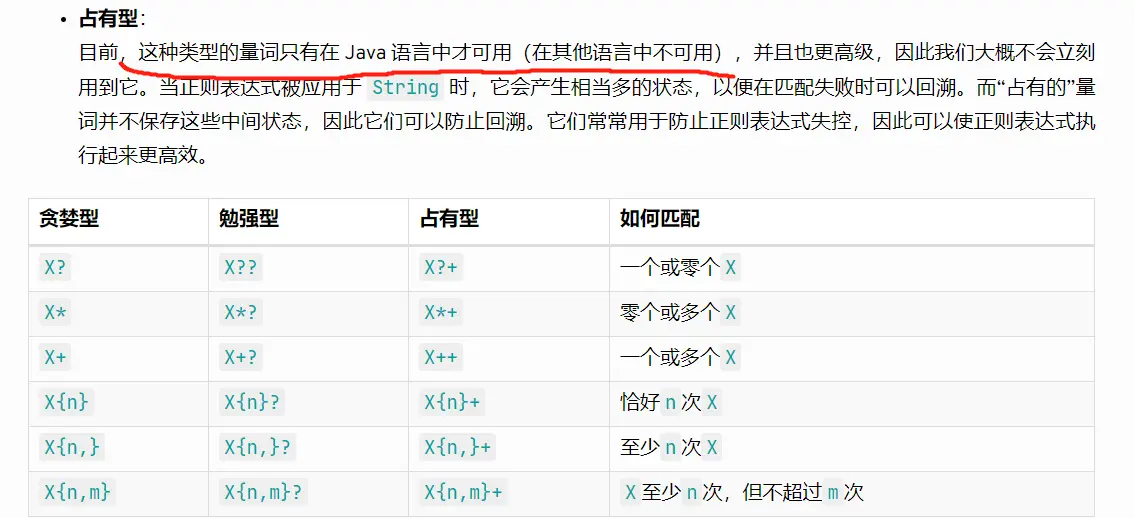
正则表达式
Java 正则表达式的几种匹配模式:
正则表达式的使用方式:先用 Pattern.compile 从字符串创建 Pattern,然后通过 Pattern 对具体字符串生成 Matcher。然后调用 Matcher 实例的 find 方法遍历。
此外 String 本身的 split 和 matches 接受正则表达式。String 的 replace 方法接受的是字符或者字符序列,而 replaceAll 接受的是表示正则表达式的字符串。
正则表达式的分组:完整的正则表达式自是一组,是 0 号,不算在组数当中。例子:

lookingAt 方法则要求从开头完成匹配。matches 要求整个字符串完成匹配(相当于 String 的 matches 方法的另外一种形式)。两者都不保留当前状态,不会和 find()相互干扰。
构造 Pattern 的时候还能指定标记。在这些标记中,Pattern.CASE_INSENSITIVE、Pattern.MULTILINE 以及 Pattern.COMMENTS(对声明或文档有用)特别有用。请注意,你可以直接在正则表达式中使用其中的大多数标记,只需要将上表中括号括起来的字符插入到正则表达式中,你希望它起作用的位置即可。Pattern.COMMENTS 能够跳过空白和 # 注释行。
Matcher 还有个有用的方法,允许在匹配到一个部分的时候给定一个字符串去做替换。这样就不用拘泥于正则表达式本身的替换规则了。
StringBuffer sbuf = new StringBuffer();
Pattern p = Pattern.compile("[aeiou]");
Matcher m = p.matcher(s);
// Process the find information as you
// perform the replacements:
while(m.find())
m.appendReplacement(sbuf, m.group().toUpperCase());
// Put in the remainder of the text:
m.appendTail(sbuf);
在上面的代码结束后,现在被匹配的组中的字符都变成了大写。由于是一步一步 append 的,所以 Matcher 的 appendReplacement 和 appendTail 接受StringBuilder或者StringBuffer作为参数。这个StringBuffer并不是和nio中Channel相关的Buffer视图,而是一个老的用于字符串构造的类,它有着同步的好处,但因此性能不及StringBuilder。
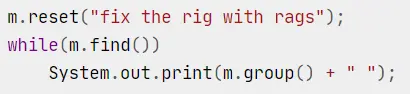
通过 reset() 方法,可以将现有的 Matcher 对象应用于一个新的字符序列:
💡 Java 中的 main 方法得到的参数是不包含 java 命令和启动点名称的,只含有真实传给 java 程序的参数。而 NodeJS 则把 node 和文件名都一起保留了,遵守了 C 的规定。
Scanner
Scanner 可以对字符序列进行扫描。它会吞掉 IOException,需要通过调用方法来检查。Scanner 的 hasNext 方法还能使用一个表示正则表达式的字符串来进行匹配。
💡 在配合正则表达式使用扫描时,有一点需要注意:它仅仅针对下一个输入分词进行匹配,如果你的正则表达式中含有分隔符,那永远不可能匹配成功。默认的分隔符是空白,也可以自己设置。
StringTokenizer 可以按照空白分隔字符串。但是现在有了 Scanner,它能够按照任意方式分隔字符串,而且取当前区域结果的时候还能够按照给定的方式来进行类型转换。所以 StringTokenizer 显得没有什么用了。
RTTI
instanceof 的检查再转换比 try-catch 捕获 ClassCastException 的性能高得多。这里是和文件系统操作不同的一个地方。instanceof支持子类型。而Class的equal方法要求是同一个类型。
泛型
协变
定义的时候给定泛型边界:
class
CanineHero<POWER extends SuperHearing & SuperSmell>
extends SuperHero<POWER> {
// ...
}
必须满足多个边界的时候用&符号连接。(联想处理多个异常的时候用|连接)
虽然在定义的时候可以使用多个类型来作为边界约束,但是使用的时候,通配符只能限制一个边界:

不用通配符限制边界会直接无法编译通过!
逆变
还可以走另外一条路,即使用超类型通配符。这里,可以声明通配符是由某个特定类的任何基类来界定的,方法是指定 <?super MyClass> ,或者甚至使用类型参数: <?super T>(尽管你不能对泛型参数给出一个超类型边界;即不能声明 <T super MyClass> )。这使得你可以安全地传递一个类型对象到泛型类型中。因此,有了超类型通配符,就可以向 Collection 写入了:
// generics/SuperTypeWildcards.javaimport java.util.*;
public class SuperTypeWildcards {
static void writeTo(List<? super Apple> apples) {
apples.add(new Apple());
apples.add(new Jonathan());
// apples.add(new Fruit()); // Error
}
}
因为边界限定了容器是Apple的基类,因此添加Apple的子类被编译器认为是安全的。super 和 extends 的限制虽然有一点差异,但是本质上都是解决了类似容器的问题。super保证了只能放苹果,而extends则保证了只能取苹果。它们需要配套使用。
单个通配符 ?可以表示任意类型,但必须是一个具体的类型。更重要的是,他可以准确规定某部分的类型,而忽略其他部分的类型。
public class UnboundedWildcards2 {
static Map map1;
static Map<?,?> map2;
static Map<String,?> map3;
static void assign1(Map map) {
map1 = map;
}
static void assign2(Map<?,?> map) {
map2 = map;
}
static void assign3(Map<String,?> map) {
map3 = map;
}
// ...
}
单个通配符也没有(在编译时)保存类型信息,但是Holder<?>和Holder是有区别的。前者表示一个具体的类型,不能是所有类型,因此不能往里面放Object类型的对象,会编译错误;后者是表示所有类型(any和all的区别),因此可以放Object,但会得到编译器警告。
把一个Holder<Any>对象转换成Holder<?>是可以的。上面 Holder<?> 放东西会出错是因为调用了具体的方法,放东西的时候Any需要转换成 T,但是 T 又是不知道的。Holder 则是把Any转换成了Object,这是没给泛型参数时的一种默认实现。
捕获转换
Holder 不能被泛型方法 <T> void f1(Holder<T> holder) 接受。但是能够被方法 void f2(Holder<?> holder) 接受。后者不是一个泛型方法,他本身也是通配的。有趣的是,在 f2 中可以调用 f1,使得 Holder<T> 看似(编译器也支持)可以从 Holder<?> 中获取信息。但是我们不能使用返回值,因为方法 1 中的 T 类型对于方法 2 是未知的。
泛型中的棘手问题
实现参数化接口
一个类不能实现同一个泛型接口的两种变体,由于擦除的原因,这两个变体会成为相同的接口。下面是产生这种冲突的情况:
// generics/MultipleInterfaceVariants.java// {WillNotCompile}package generics;
interface Payable<T> {}
class Employee implements Payable<Employee> {}
class Hourly extends Employee implements Payable<Hourly> {}
Hourly 不能编译,因为擦除会将 Payable<Employe> 和 Payable<Hourly> 简化为相同的类 Payable,这样,上面的代码就意味着在重复两次地实现相同的接口。十分有趣的是,如果从 Payable 的两种用法中都移除掉泛型参数(就像编译器在擦除阶段所做的那样)这段代码就可以编译。
在使用某些更基本的 Java 接口,例如 Comparable<T> 时,这个问题可能会变得十分令人恼火,就像你在本节稍后看到的那样。
重载
下面的程序是不能编译的,即使它看起来是合理的:
// generics/UseList.java// {WillNotCompile}import java.util.*;
public class UseList<W, T> {
void f(List<T> v) {}
void f(List<W> v) {}
}
因为擦除,所以重载方法产生了相同的类型签名。
古怪循环泛型
class SelfBounded<T extends SelfBounded<T>> {// ...
循环古怪泛型的方法中要求的参数 T 必须是这个类型自身,用其他的方法就不能表达这个类型本身,因为这个类型本身的描述就是不确定的,对不同的类型来说不一样。
能够想到的一个应用是interface SelfComparable<T extends SelfComparable>。但是总的来说不如 C++模板在编译时强制的花样多。用处不是很大……
假定 B 类继承于 A 类。则 A 类的非 private 方法在 B 类重写时可以使用返回值协变(重载方法的参数是不支持协变也不支持逆变的)。如果 A 类是一个泛型类,那么 B 类中相当于被插入了具体的 A 类的代码。
Java 数组
parallelPrefix 并行前缀
在数组计算的时候很有用。比如调用Arrays.parallelPrefix(nums, Integer::sum);前后的数组元素变化情况如下:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 1, 3, 6, 10, 15, 21, 28, 36, 45]
并发
尽可能使用流的并发支持和 CompletableFuture 完成任务。传统的 Future 需要手动检查结果,而 CompletableFuture 能够以非常灵活的方式把任务链接起来。
ExecutorService 一旦打开就需要用 shutdown 来让他完成任务后自动退出。否则,因为它管理的线程不是 daemon 线程,主线程完成任务后,程序还有线程在运行,不会退出。以往是向 ExecutorService 提交任务,然后获取 Future,但是现在推荐直接通过 CompletableFuture 的静态方法来创建 CompletableFuture 对象。这不仅能够更好支持并发,而且使用起来也更简单。
CompletableFuture 开启的线程是守护线程,如果不手动 join,程序在没有非守护线程时就会中止。
低层级并发
AtomicBoolean 等类(取名方法是 Atomic 加上包装类名称)专门对基本数据类型实现了原子操作。
volatile 不是用来支持并发的——除非明确自己的模型能够使用它来避免数据竞争。它能够保护基本数据类型的读或写被其他线程可见,而不会发生数据断片的情况(比如 32 位机器写 64 位数据时候可能需要用两次操作,这当中可能会发生上下文切换)。volatile 能够保证单次读或者写的安全,但是无法保证自增等的安全。
The effect of the
volatilekeyword is approximately that each individual read or write operation on that variable is made atomically visible to all threads.Notably, however, an operation that requires more than one read/write – such as
i++, which is equivalent toi = i + 1, which does one read and one write – is not atomic, since another thread may write toibetween the read and the write.The
Atomicclasses, likeAtomicIntegerandAtomicReference, provide a wider variety of operations atomically, specifically including increment forAtomicInteger.
对 volatile 数据的读写还会产生内存屏障(C++内存模型中有讨论)。由于内存屏障的作用,JVM 不会对操作进行跨越屏障的排序,也保证了其他非 volatile 变量需要满足的内存顺序要求(借助这个特性,有些变量本身不是 volatile,但也能够解决数据竞争)。这项特性在 Java 1.5 才实现。
使用 synchronized 来锁定该方法所属的对象。synchronized 可以用于代码块或整个方法,它还可以接受一个参数来替代默认参数 this。
也能够显式使用锁。比如private Lock lock = new ReentrantLock();
并发也得到了容器的支持。比如阻塞式的队列,或者依靠写时(部分)复制实现的安全并发容器。
(不一定对,个人想法)直观印象(C++并发实战中稍微读了一下)是链式结构容易实现并发甚至可能无锁化,但是数组结构难,因为链式结构可以拆分成很小的部分,大大缩小竞争域。