CUDA Kernel 常用 float 类型这件事
本文分别讨论双精度、单精度、半精度的浮点数计算,最后提及混合精度。在 CPU 方面,仅考虑 x86-64 CPU 和 GNU/Linux 上的 GCC 编译器;GPU 方面仅考虑 NVIDIA GPU。
GPU 上双精度计算慢在哪里?
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#arithmetic-instructions 以上链接说明:GPU 双精度浮点数运算比单精度浮点数慢,在有些架构(很多 $x.y~(y \ne 0)$ 运算能力的 GPU 都是游戏卡)上甚至慢得多。除了指令慢之外,double 类型也不利于 cache 和全局内存带宽。
https://forums.developer.nvidia.com/t/use-float-rather-than-double-in-a-kernel/107363 A 64 bit double variable takes 2 registers. A 32 bit float can be stored in 1 register. 双精度浮点数的使用会增加单个 CUDA 线程对寄存器数量的需求,从而减少实际上同时可以运行的线程数。
怎么正确使用单精度类型?——谨防隐式转换成双精度
CUDA 和 C/C++ 都不会先将 float 转 double 再计算,除非……
https://godbolt.org/z/Me66bEeaa 我在本地尝试构造浮点数精度损失,但是无法构造出来,去 compiler explorer 一看发现实际上单精度浮点数被转换成了双精度浮点数计算。为什么呢?
https://godbolt.org/z/jM6sGn5je 罪魁祸首其实是表达式中的那些常量,他们都是 double 类型的,会导致其他 float 参数被转换成 double。
https://godbolt.org/z/4hevdr7Mo 写模板函数时如果需要使用浮点数字面量,最好是先写成 double 类型(比如 3.14 而不是 3.14f)然后在前面做类型强制转换,字面量的类型转换可以由编译器完成,而无需运行时使用类型转换指令。
template <typename T>
__device__ __host__ T helper(T a, T b) {
return ((a * (T)3.4) * b * (T)1.2) * a * b / (T)0.7;
}
这个类型转换规则是编程语言的规定,不分 CPU 还是 GPU。那 float 什么时候会没遇到 double 还自动转换成 double 呢?在可变长参数函数中会这样。比如 https://godbolt.org/z/4PeK6coMn 中对 printf() 的传参导致 cvtss2sd 指令的出现。
Integer/floating-point promotion: 难道 float 在计算时不会先转成 double 吗?这是记混知识了。整数参与计算时是会至少 promote 到 32 位的(小于 int 表示范围的会 promote 到 int),而浮点数只有其他参数表数范围更大时才会发生 promotion。可以参考 https://en.cppreference.com/w/c/language/conversion ,里面有个值得注意的是 0UL - 1LL 计算时两个参数都会被转换成 unsigned long long 类型。
实验:看看基础类型的乘法汇编是什么?
https://godbolt.org/z/T8nsKWxGs CPU 上 float 和 double 使用相同的寄存器,却使用不同的指令去计算(编译器会追踪一个寄存器存储的真实类型,比如 eax 既能存 int 又能存 unsigned,xmm0 也是既能存 float 又能存 double);CPU 上 int 和 long long 使用不同的寄存器,指令却是一样的(只区分有无符号)。
https://godbolt.org/z/4P65dK8nq GPU 上 float 和 double 计算使用不同的寄存器和不同的指令,int 和 long long 也是用不同的寄存器和不同的指令。(double 类型实际上是用了两个 32 位寄存器?只是 PTX 虚拟汇编中用 f64 表示双精度浮点数。)
我的猜测:
进行数值计算时,只要还没有发生存储步骤(寄存器存不下了,需要写回内存),CPU 就能用高精度的寄存器来暂存计算结果,因而精度更高。这显然不对,因为单精度计算的指令和双精度计算的指令不同,即便都是在 xmm0(举例)中位表示也不同。- 因为知道“GPU 上双精度计算慢”,大家写 CUDA kernel 时都刻意采用 3.14f 这样的字面量,存储结构也是用 float 类型,自然比不上 CPU 上双精度浮点数的计算精度。在 CPU 上,由于 double 和 float 的性能差异没有那么大,往往直接使用 double。
实验:验证中间表示类型会影响计算精度
假定所用到的所有输入,还有返回值都是 float 类型,保证输入相同。
#include <cstdio>
#include <thrust/device_vector.h>
// T 是返回值/参数/字面量的类型,U 控制单精度计算还是双精度计算。
// (float) 强制转换保证字面量总能被单精度浮点数表示,排除输入不同造成的差异。
template <typename U, typename T> __device__ __host__ T calc(T a, T b) {
// return (U)a * (float)3.4543522434343 * (float)-1.244445135 * b * a /
// (float)0.7434333332 + (float)0.453535433338;
// 写成一行和分开写,效果一样
U x = a;
x *= (float)3.4543522434343;
x *= (float)-1.244445135;
x *= b;
x *= a;
x /= (float)0.7434333332;
x += (float)0.453535433338;
return x;
}
template <typename U, typename T>
__global__ void calc_kernel(T *a, T *b, T *result) {
*result = calc<U, T>(*a, *b);
}
template <typename U, typename T> T cuda_calc(T a, T b) {
thrust::device_vector<T> v(3);
v[0] = a;
v[1] = b;
T *p = v.data().get();
calc_kernel<U><<<1, 1>>>(p, p + 1, p + 2);
return v[2];
}
template <typename U, typename T> T cpu_calc(T a, T b) {
return calc<U, T>(a, b);
}
int main() {
float a = 13.42433332;
float b = 3.1487223258;
{
printf("cuda_calc: ");
float x = cuda_calc<float>(a, b);
float y = cuda_calc<double>(a, b);
if (x == y) {
printf("x == y\n");
} else {
printf("x - y = %.8f\n", x - y);
}
}
{
printf("cpu_calc : ");
float x = cpu_calc<float>(a, b);
float y = cpu_calc<double>(a, b);
if (x == y) {
printf("x == y\n");
} else {
printf("x - y = %.8f\n", x - y);
}
}
}
代码中的 U 为 float 时使用的是单精度计算,U 为 double 时使用双精度计算。结果为:
cuda_calc: x - y = 0.00024414
cpu_calc : x - y = 0.00024414
PyTorch 是怎么做的?
https://github.com/pytorch/pytorch/blob/e890d888d916b4f38b383a59e0e9445513c67313/aten/src/ATen/AccumulateType.h#L136 PyTorch 在 CUDA 上计算时,如果输入是 float,中间的存储类型(acc_type)也用的是 float。
https://github.com/pytorch/pytorch/blob/e890d888d916b4f38b383a59e0e9445513c67313/aten/src/ATen/AccumulateType.h#L155 PyTorch 在 CPU 上计算时,如果输入是 float,中间的存储类型用的是 double。
https://github.com/pytorch/pytorch/issues/113414 (该 issue 来自 2023 年 11 月)这里说如果使用 float 作为单精度计算的累加类型,会导致 batchnorm 的单元测试失败。GPU 能过测试但 CPU 不能过测试的原因是什么呢?我写了两外一篇文章来看 torch 的代码(但也是瞎猜),见 PyTorch 的 CPU 计算为什么使用 double 作为 32 位浮点数的累加类型? 。
https://github.com/pytorch/pytorch/blob/2ad011ca73f68185783ec9afeb730615769a3fca/aten/src/ATen/native/cpu/batch_norm_kernel.cpp#L226-L228 这里的代码注释说明了 CPU 上 batch_norm 的累加计算使用 at::acc_type<scalar_t, /* is_cuda */ false> 作为中间类型,相同的注释也多次在此文件的其他函数中出现。
Note
我不觉得把单精度浮点数转双精度浮点数就是误差(反而精度更高呢),但是我们老师认为 PyTorch 是深度学习的金标准,计算结果和它不一致就是误差。为了“减少误差”,写单精度的 kernel 时就要避免隐式转换到双精度。我倒觉得始终使用单精度计算只是为了速度,拿精度换速度也是合理的。
FP32 计算精度低并不是 GPU 的原罪
本实验中 CPU 和 GPU 的表现一致。这说明写 kernel 时将“FP32 四则运算的简单组合在 GPU 和 CPU 计算的结果不同”归咎于“GPU 就是有误差”是不对的,很可能是写法有问题。
Note
2024 年 12 月 10 日:我最近看到有个说法:在 TF32 出现之前,很多 GPU 制造商已经悄悄通过降低浮点数舍入前的最大精度来提高计算速度。
IEEE754 只是规定了浮点数扩展格式的最低要求,并没有对编码方式做严格规定,x86 就有一个 80 位的浮点数扩展格式(下面这个 integer part 有点特殊,详见维基百科)。这样的扩展格式一般是在中间计算过程中使用的,尤其是在 x86 指数运算时对精度的作用显得非常重要。降低中间表示的精度来提速在理论上是可行的。

CPU 和 GPU 上的半精度计算
先看 CPU:GCC 提供了 _Float16 扩展。从 汇编代码 可以看出该类型借助了软件支持,而且在计算时也是先转换成单精度的。所以 CPU 上刻意去用半精度会很慢。(在 C++23 还有 std::float16_t,不过我想也差不多。)
再看 GPU 上的半精度类型 __half,使用该类型需要包含头文件 cuda_fp16.h。 从 汇编代码 可以看出,半精度类型是一种用户定义类型(一个类),PTX 代码也比 float 和 double 复杂太多。这样就会得到 CUDA kernel 上半精度计算很慢的结论,和我们平时训练模型的实际感受不一致啊?
为此我找到了论坛的一个回答:https://forums.developer.nvidia.com/t/poor-half-performance/111626 There is no 16-bit register on the device. They are all 32-bits. To get double performance of a float, you need to use half2. Where you package two half precision variables in one register. And then use the appropriate intrinsic. Moderator 表示 __half 类型没有对应的寄存器,所以很慢,要快的话得用 __half2 类型。该类型同样需要 cuda_fp16.h 头文件。根据 mod 的说法,使用 __half2 类型和相应的内置计算函数可以得到近似于单精度计算两倍的速度。
在 CPU 的 SIMD 计算中,是不是也可以像 GPU 一样实现把多个半精度数据打包在大的寄存器里,从而让半精度计算变快呢?我看了一下只有较新的 CPU 才在 AVX512 中支持 16 位浮点数,而以前的老 CPU 计算 16 位浮点数要转成 32 位浮点数,转换开销让向量计算得不偿失。
总结:CUDA kernel 上双精度换单精度,代码逻辑不需要改,速度就能提升。单精度换半精度,就要使用 __half2 类型和一些内置函数了,写起来会稍微麻烦一点。
Tensor Core 和混合精度计算
从前面的实验我们可以看出:中间表示类型的不同会影响计算的类型,从而影响计算精度和计算速度。混合精度计算就是为了提高计算速度,使用了精度更小的中间表示类型。
PyTorch 的一篇文档 描述了 PyTorch 在什么场合下会有计算差异。其中提到 TensorFloat-32 (TF32) on Nvidia Ampere (and later) devices 和 Reduced Precision Reduction for FP16 and BF16 GEMM。后者是 FP16 计算,在很多 GPU 上都有支持;前者是 TF32 计算,最早出现在 A100 的第三代 Tensor Core 中。
V100 的第一代 Tensor Core 支持了 FP16+FP32 的混合精度计算
Tensor Core 在 NVIDIA Volta 上就已经出现了,本质就是以混合精度计算提高矩阵乘法速度。第一代 Tensor Core 使用 FP16+FP32 加速计算。附上演化史:
这张图信息非常多,不仅说明了很多数据类型的计算是在什么时候被支持的,还说明了 Tensor Core 是在 Volta 架构开始支持的。Tensor Core 一直都不支持 FP32 计算!?
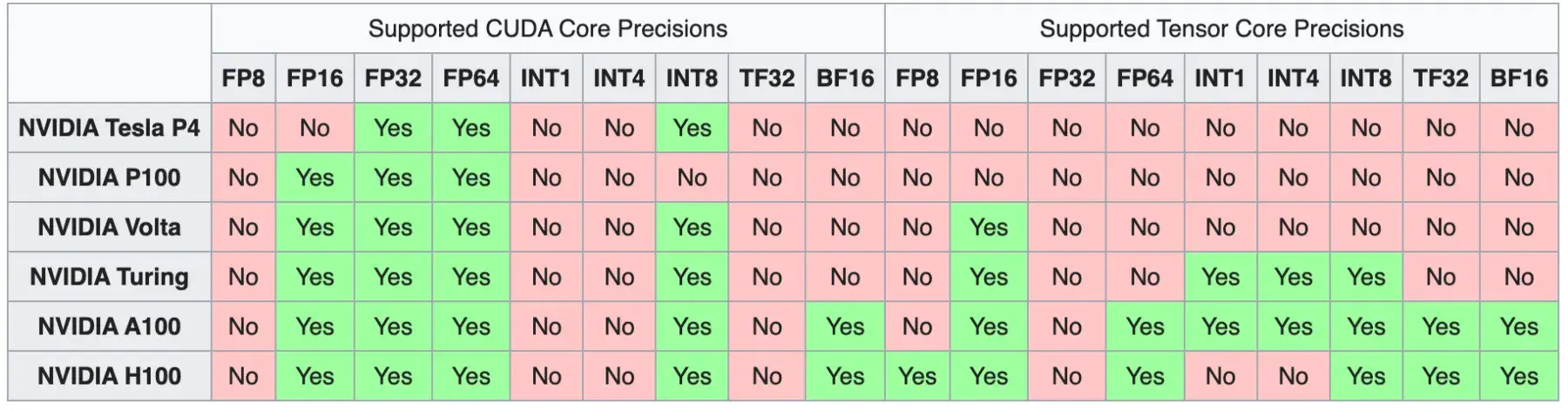
更详细的计算支持可以参见 CUDA#Data_types 和 CUDA#Tensor_cores 。H100 属于 Hopper 架构。RTX 3090 和 A100 属于 Ampere 架构。RTX 4090 属于 Ada 架构,表上没有。RTX 4090 计算能力是 8.9,从维基百科见其相比 Hopper 的 Tensor Core 多了 INT1 和 INT4 支持。FP64 表上写的是 speed tbd。NVIDIA Ada 架构白皮书 第 24 页提到 4090 支持了 FP16 / BF16 / INT4 / INT8 / TF32,没有提到 INT1。第 7 页提到 Ada AD102 GPU 含有少量的 FP64 Core,计算性能低,但是为程序提供了兼容支持。AD102 就是 RTX 4090。
Note: The AD102 GPU also includes 288 FP64 Cores (2 per SM) which are not depicted in the above diagram. The FP64 TFLOP rate is 1/64th the TFLOP rate of FP32 operations. The small number of FP64 Cores are included to ensure any programs with FP64 code operate correctly, including FP64 Tensor Core code.
A100 的第三代 Tensor Core 新增了 TF32 类型
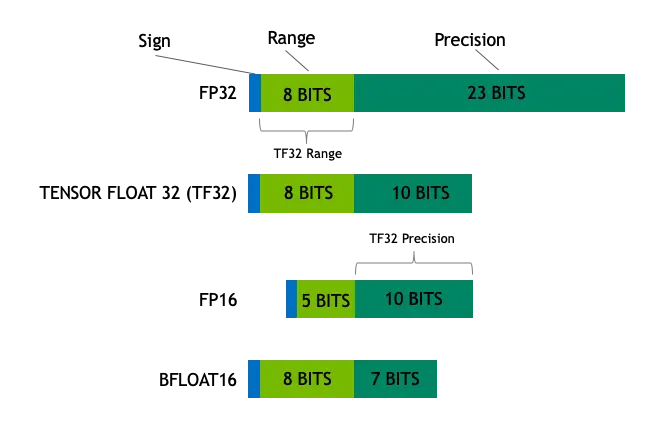
TF32 类型是什么呢?英伟达的博客 提到 TF32 类型是 8 位指数和 10 位尾数,它的指数位数和 FP32 一致,而尾数位数和 FP16 一致。
TF32 Tensor Cores operate on FP32 inputs and produce results in FP32. Non-matrix operations continue to use FP32.
也就是说,第三代 Tensor Core 可以用 TF32+FP32 混合精度计算矩阵乘法,即中间表示会从单精度浮点数缩小为 TF32,在提升速度的同时还能保持和 FP32 几乎一样大的表数范围。
根据英伟达的文档 https://developer.nvidia.com/automatic-mixed-precision ,A100 还是能够使用 FP16 来进行混合精度计算,只是提供了 TF32 这种表数范围更大的新选择(比 FP16 慢):
On Ampere GPUs, automatic mixed precision uses FP16 to deliver a performance boost of 3X versus TF32, the new format which is already ~6x faster than FP32.
TF32 会带来什么样的改变?
TF32 有和 FP32 相同数量的指数位,是被设计来平替 FP32 的。因此,一些 NVIDIA 计算库的默认计算方式有变化。在没有 TF32 的时候,想要使用 FP16 混合精度计算需要显式设置计算模式,因此不会无缘无故发生精度损失;TF32 出现之后就不一样了!
Note
TF32 只能平替 FP32(不会替换 FP16 或者 FP64),场合包括卷积、矩阵乘法,不包括优化器和求解器。
根据 https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/ :
- cuDNN:在进行 FP32 计算时,如果有 TF32 卷积 kernel 可用则使用 TF32,否则使用 FP32。
- cuBLAS:cuBLAS 被广泛用于需要 FP32 精度的场合(因为 cuBLAS 是线性代数库,并不是深度学习计算库),所以默认值还是 FP32,但是可以通过一些设置来启用 TF32 计算模式。为英伟达进行优化过的深度神经网络计算框架(原文是 NVIDIA optimized deep learning frameworks,我的理解是 PyTorch、Tensorflow 这类框架)会根据当前的计算任务调用
cublasSetMathMode(),以在一部分场合优选 TF32 计算、在其他场合仍然使用 FP32 计算。 - cuSOLVER:默认值没有变化,总是会使用 API 参数中指定的精度。
- cuTENSOR:默认值没有变化,总是会使用 API 参数中指定的精度。
该文章的结论是:尽管 FP16/BF16 混合精度仍然是最快的选择,TF32 使得单精度计算可以得到隐式的加速。
我们如何使用混合精度计算?
要在 PyTorch 中使用混合精度,可以用 torch.amp,其中 amp 是自动混合精度的意思。
要在 CUDA C++ 中利用混合精度计算,可以选择 cuBLAS、cuDNN 等 NVIDIA 库。它们有混合精度计算的支持。
要在 CUDA kernel 中利用 Tensor Core 进行混合精度计算,需要显式调用一些基础 API,包括引入头文件 mma.h 和使用 nvcuda::wmma 名字空间下的一些函数。可以参考 https://leimao.github.io/blog/NVIDIA-Tensor-Core-Programming/ 。CUDA C++ WMMA API 的调用级别是 warp,而不是每线程。
GPU 如何协调 CUDA Core 和 Tensor Core 之间的任务呢? 我的理解是:每个 block 是整体派发给 SM 的(当然一个 SM 有可能被分配多个 blocks),然后 SM 分成多个 SMSPs(SM Sub-Partitions,SP 不是流处理器),而 CUDA Core(在 AMD GPU 上叫做 SP,Streaming Processor)和 Tensor Core 的地位差不多是算术运算单元,都在 SMSP 的内部。由 SMSP 内部的 warp scheduler 来协调一个 warp 要么使用 CUDA Core 来进行 SIMT 计算,要么使用 Tensor Core 来进行矩阵计算。CUDA Core 的数量对应于一次能进行的浮点数 / 整数运算最大数量,它不是完整的线程执行器,而只是计算单元而已。A100 白皮书 22 页显示 A100 每个 SM 有 4 个 SMSP,但是一个 SM 最大支持 64 个 warps,所以 A100 的一个 SMSP 上可以最多有 16 个 warps,这说明 1 个 warp scheduler 可以同时调度多个 warps。参考:
- https://stackoverflow.com/questions/16986770/cuda-cores-vs-thread-count
- B 站视频:NVIDIA英伟达Tensor Core架构发展(中)【AI芯片】GPU架构05
- Ampere 白皮书:Table 5. Compute Capability: GP100 vs GV100 vs GA100
- Ampere 白皮书:SM 架构图
- Hopper 白皮书:SM 架构图
https://www.reddit.com/r/CUDA/comments/qk9rbs/i_dont_understand_how_cuda_kernel_works_within/ The TensorCores are specialized execution units within the SM.
https://forums.developer.nvidia.com/t/concurrent-execution-of-cuda-and-tensor-cores/222985/8 该回复建议参阅 A100 白皮书,可以看到 Tensor Core 位于 SM 里面。该文档还指出 A100 有 128 个 SMs,每个 SM 有 4 个 Tensor Cores 和 64 个 FP32 CUDA Cores。下面几张图放的是 A100 的技术规格。(2025/3/19 V100 的老一代 Tensor Core 在一个 SM 中有 8 个,可查白皮书,A100 减少了单 SM 中 Tensor Core 的数量。)

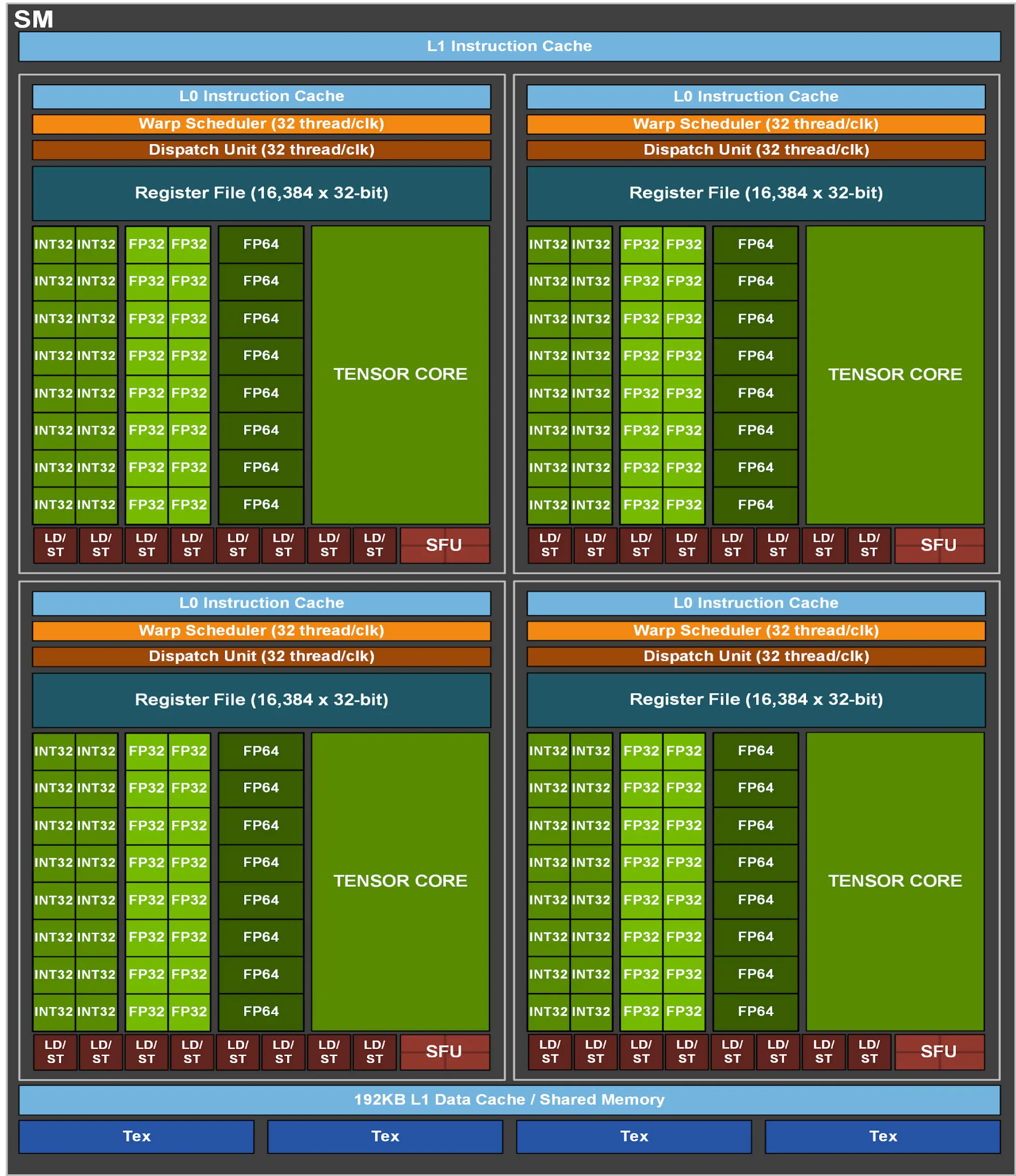
- 共享存储部分:纹理内存、L1 指令缓存、L1 数据缓存。
- L1 数据缓存和共享内存是共用一个存储器件的,此多彼少,共享内存的占用大小可以通过 CUDA API 配置。
- 子单元:SMSP
- 控制部分:
- Warp 调度器
- 指令派发器。warp 调度器选择 warp(任务)来执行,指令派发器负责具体任务的指令发射。
- 存储部分:
- L0 指令 cache(注意是指令的 cache)
- LD/ST:存储加载单元
- 寄存器文件
- 计算部分:
- 整型和浮点运算单元(CUDA Core 数量反映于 FP32 计算单元的数量,INT32 计算单元数量与其相同;FP64 少于,甚至可能显著少于 FP32 单元的数量)
🤔 我觉得可以理解为线程 = CUDA Core + 每线程的维护数据。然后
CUDA Core线程以 warp 形式组织。 - Tensor Core
- SFU(特殊函数计算单元,比如 sin/tan/exp/log/sqrt 等数学函数)
- 整型和浮点运算单元(CUDA Core 数量反映于 FP32 计算单元的数量,INT32 计算单元数量与其相同;FP64 少于,甚至可能显著少于 FP32 单元的数量)
- 控制部分:
A100 白皮书第 20 页 画了 A100 更完整的图,可以看到 SM 一下子变得很小、很多。图片有点大放在这里也看不清楚,最好还是去链接里面看原图。

第 19 页提到:
The NVIDIA GA100 GPU is composed of multiple GPU Processing Clusters (GPCs), Texture Processing Clusters (TPCs), Streaming Multiprocessors (SMs), and HBM2 memory controllers.
The full implementation of the GA100 GPU includes the following units:
- 8 GPCs, 8 TPCs/GPC, 2 SMs/TPC, 16 SMs/GPC, 128 SMs per full GPU
- 64 FP32 CUDA Cores/SM, 8192 FP32 CUDA Cores per full GPU
- 4 Third-generation Tensor Cores/SM, 512 Third-generation Tensor Cores per full GPU
- 6 HBM2 stacks, 12 512-bit Memory Controllers
后面还提到了另外一个版本(The NVIDIA A100 Tensor Core GPU implementation of the GA100 GPU)的配置,看起来像是缩水版。