读英伟达博客:CUDA Wrap 级原语
原文
https://developer.nvidia.com/blog/using-cuda-warp-level-primitives/
笔记
Warp 内规约
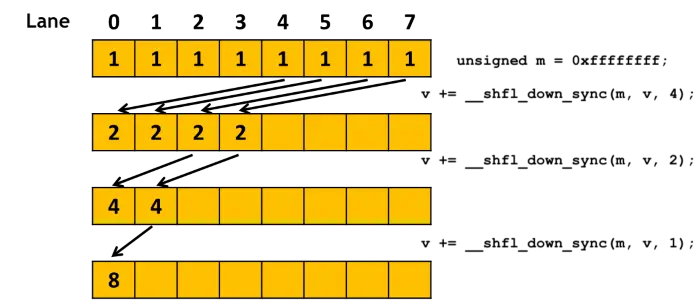
#define FULL_MASK 0xffffffff
for (int offset = 16; offset > 0; offset /= 2)
val += __shfl_down_sync(FULL_MASK, val, offset);
先在 warp 内用原语规约,比在 block 级别用共享内存规约快很多。(虽然也有 __reduce_add_sync() 函数,但是截至 2024 年 9 月 5 日只支持 unsigned 和 int 类型,给浮点数做规约就要用 __shfl_xx_sync() 系列。)
CUDA 9 的相关 API
直接从原博客摘录:
- Synchronized data exchange: exchange data between threads in warp. 形式为
__xx_sync(mask, val)。
__all_sync,__any_sync,__uni_sync,__ballot_sync__shfl_sync,__shfl_up_sync,__shfl_down_sync,__shfl_xor_sync__match_any_sync,__match_all_sync- Active mask query: returns a 32-bit mask indicating which threads in a warp are active with the current executing thread.
__activemask- Thread synchronization: synchronize threads in a warp and provide a memory fence.
__syncwarp
说明:
__syncwarp()只保证在运行此函数的时候在 warp 内达成同步,但不保证同步后的下一条语句依然由 warp 内所有的线程参与执行。应该只能用来同步到共享内存的写入和读取?__xx_sync(mask, val)不等于__xx(val)和__syncwarp()的组合。__balloc_sync(mask, pred)是从 mask 中找出 pred 非零的、还未退出的线程的集合,返回方式为 32 位掩码。__match_any_sync(mask, val)是把 val 相同的分区到一起,返回当前区的 mask。__match_all_sync(mask, val, pred)要么返回 mask(mask 里的所有线程都分区到一起),要么返回 0。传出参数 pred 根据是否成功设置成 true 或者 false。
Warp 内同步
void __syncwarp(unsigned mask=FULL_MASK);
考虑不使用 __shfl_down_sync(),而是用类似共享内存内累加的方式完成 warp 内的累加。
❌ 错误的 warp 内累加:
unsigned tid = threadIdx.x;
// Incorrect use of __syncwarp()
shmem[tid] += shmem[tid+16]; __syncwarp();
shmem[tid] += shmem[tid+8]; __syncwarp();
shmem[tid] += shmem[tid+4]; __syncwarp();
shmem[tid] += shmem[tid+2]; __syncwarp();
shmem[tid] += shmem[tid+1]; __syncwarp();
✔ 正确的 warp 内累加:
unsigned tid = threadIdx.x;
int v = 0;
v += shmem[tid+16]; __syncwarp();
shmem[tid] = v; __syncwarp();
v += shmem[tid+8]; __syncwarp();
shmem[tid] = v; __syncwarp();
v += shmem[tid+4]; __syncwarp();
shmem[tid] = v; __syncwarp();
v += shmem[tid+2]; __syncwarp();
shmem[tid] = v; __syncwarp();
v += shmem[tid+1]; __syncwarp();
shmem[tid] = v;
2025/3/25 我试了一下用 if (tid < stride) shmem[tid] += shmem[tid+stride]; __syncwarp(); 也是能工作的。这个和 blockreduce 的模式一样,用 if 条件可以保证正在被读的对象不会被写。
机会主义的 warp 级编程
原文给了一个把 per-thread 原子加改写成 per-warp 原子加的代码:
// increment the value at ptr by 1 and return the old value
__device__ int atomicAggInc(int *ptr) {
// group threads by ptr value
int mask = __match_any_sync(__activemask(), (unsigned long long)ptr);
int leader = __ffs(mask) – 1; // select a leader
int res;
if(lane_id() == leader) // leader does the update
res = atomicAdd(ptr, __popc(mask));
res = __shfl_sync(mask, res, leader); // get leader’s old value
// let every thread THINK that they did the atomic op separately
return res + __popc(mask & ((1 << lane_id()) – 1)); //compute old value
}
这段代码写的比 读英伟达博客:Warp 聚合原子操作 —— 以过滤为例 考虑得还要周到一点。代码解释可以参考刚刚给出的另外一篇博客。
其他建议
文章后面的内容大概意思是建议全部换用新的 __xx_sync() API,不要再用旧的。文章也讲了一下原来的写法中存在的风险。主要原因还是原来的 __xx() API 不接受掩码参数,不会(对指定的线程)显式同步,因此依赖于运行时逐语句的同步执行。但是新的 GPU 上的 warp 调度优化越来越多,按同一个步调执行每条语句这个条件不一定还能满足。