记一次代码合并后发生错误的定位过程
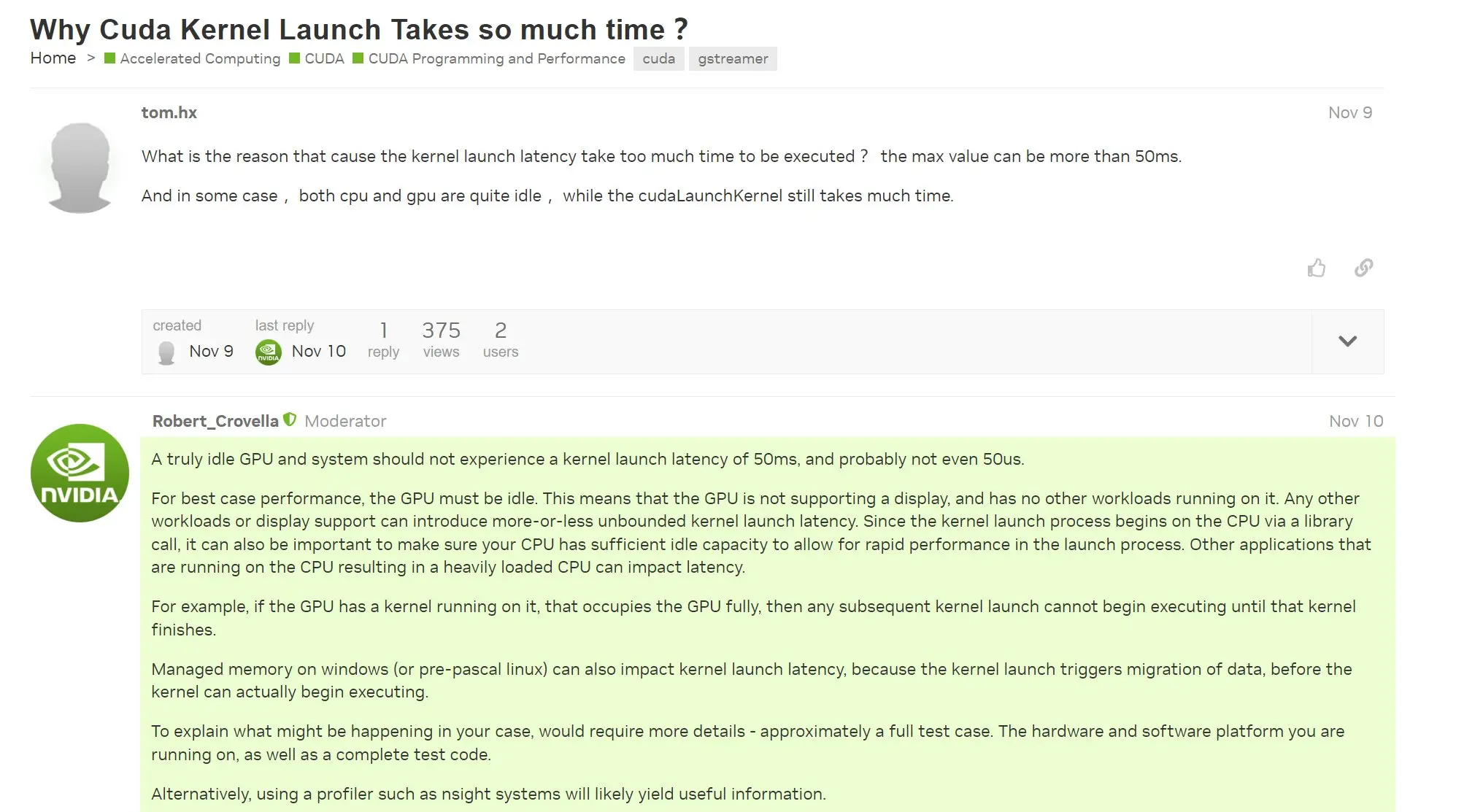
昨天晚上合并完新的代码准备提交上去但是 CI 跑不了,有一个单元测试报错。然后照着官方的 git-bisect 文档找问题。这个工具比想象中要好用很多,大部分时间都花在了构建项目上面(每次修改 HEAD 之后都要重新构建才能测试)。半个小时后锁定了问题在一个具体的提交上。
接下来我需要将我的代码和这部分有问题的代码分离。我的分支是 main,远程的分支是 origin/develop,有错误的分支是 origin2/develop。因为 main 合并了一部分 origin2/develop 的代码才导致了错误。分支的结构是这样的:
* --(若干次提交)-- origin/develop --(若干次提交)-- main
\ / (若干次提交,非线性,想要舍弃掉)
--- origin2/develop -------------------------
因为我要保证 origin/develop 这个我们的仓库总是 fast-forward 合并,所以我先以这个分支为基准创建新的本地分支。然后将在 main 中(有我的新代码)、不在 next 中(因为我本来就在 next 的位置上)、不在 origin2/develop 中(有错误)的提交重播。
git checkout -b next origin/develop
git cherry-pick main ^next ^origin2/develop


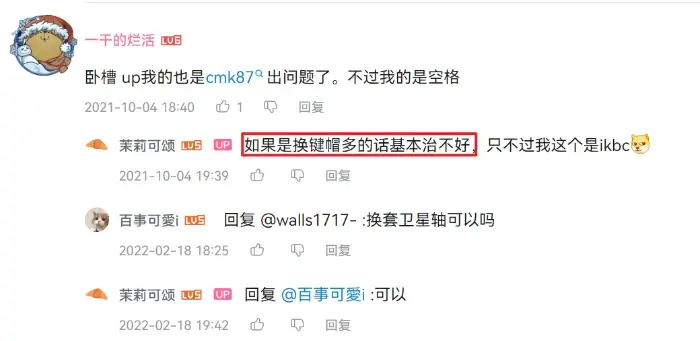 以后选键盘还是选个一开始就能接受轴体的,不要再换轴了吧 (*^_^*) 。总觉得 V75K 的卫星轴专门顺着阿尼亚轴的短行程调过(或者是挑选过),换阿尼亚轴匹配度更高一点。我现在没有别的轴体了(卖了),就试了鲸海轴,空格左侧是有
以后选键盘还是选个一开始就能接受轴体的,不要再换轴了吧 (*^_^*) 。总觉得 V75K 的卫星轴专门顺着阿尼亚轴的短行程调过(或者是挑选过),换阿尼亚轴匹配度更高一点。我现在没有别的轴体了(卖了),就试了鲸海轴,空格左侧是有