Docker 升级之后 docker-compose 无法正常启动使用 GPU 的容器
解决 docker-compose 启动的容器无法使用 GPU
最近有人升级了服务器的 docker,我们创建容器有点问题。症状是这样:在命令行用 --gpus all 参数启动的都能正常使用 GPU(可以通过运行 nvidia-smi 命令测试),但是在 docker-compose.yml 文件中指定要使用 GPU 就不行。
之前的 docker-compose.yml 文件是这样:
version: "3.9"
services:
my-dev:
container_name: ${CONTAINER_NAME}
image: ${IMAGE}
## -D 表示非 daemon 模式,-e 表示将日志输出到 stderr
## 如果有错误信息,可以用 docker compose logs 看到
command: /usr/sbin/sshd -D -e
restart: always
volumes:
- ./workspace:/workspace
- ./data:/data
ports:
- "${PORT}:22"
working_dir: /workspace
shm_size: '8gb'
pid: "host"
security_opt:
- seccomp:unconfined
cap_add:
- SYS_PTRACE
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
出错原因是 devices 一栏写的不全面,要加上 count 属性才行。可能以前的 count 默认值是 all,但是现在实测不写就不行。
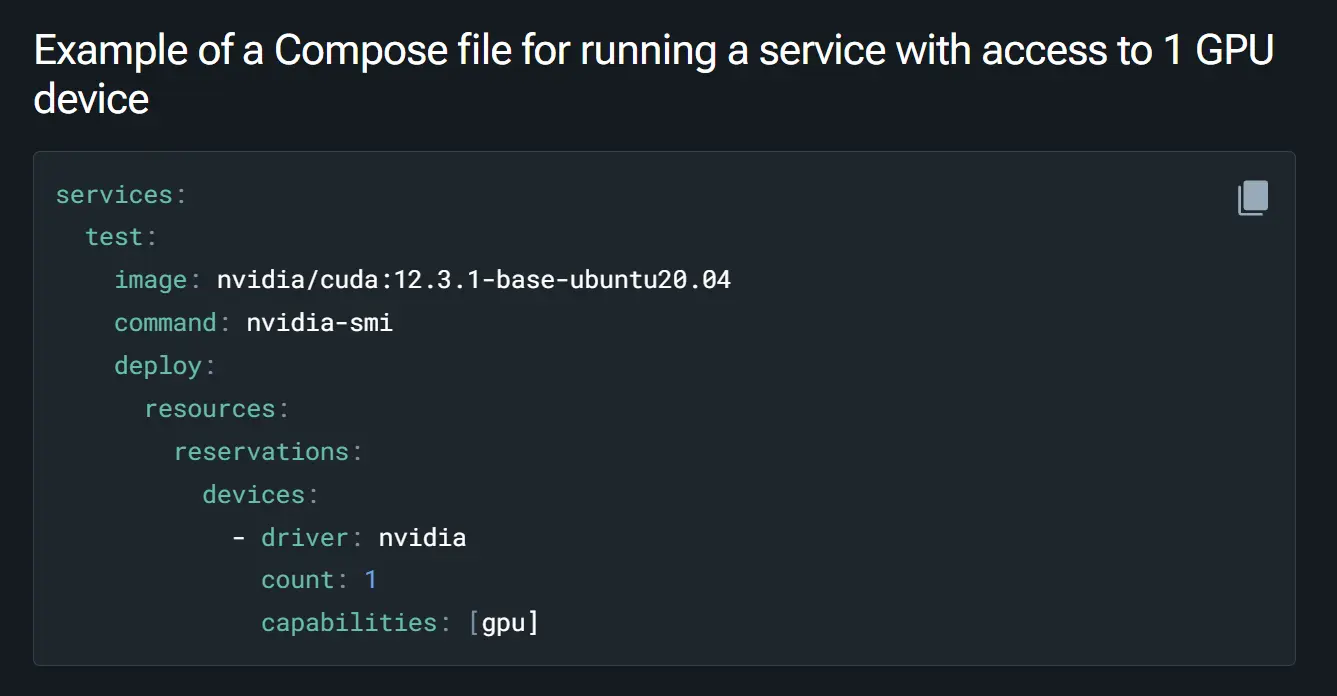

附上系统环境:
Docker Compose version v2.29.7
Docker:
Client: Docker Engine - Community
Version: 27.3.1
API version: 1.47
Go version: go1.22.7
Git commit: ce12230
Built: Fri Sep 20 11:40:59 2024
OS/Arch: linux/amd64
Context: default
Server: Docker Engine - Community
Engine:
Version: 27.3.1
API version: 1.47 (minimum version 1.24)
Go version: go1.22.7
Git commit: 41ca978
Built: Fri Sep 20 11:40:59 2024
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.7.22
GitCommit: 7f7fdf5fed64eb6a7caf99b3e12efcf9d60e311c
runc:
Version: 1.1.14
GitCommit: v1.1.14-0-g2c9f560
docker-init:
Version: 0.19.0
GitCommit: de40ad0
系统 Ubuntu 24.04.1 LTS
解决容器时不时丢失 GPU,需要重启容器
https://github.com/NVIDIA/nvidia-container-toolkit/issues/48
问题描述:
- runc 要求被注入容器的字符设备出现在 /dev/char/ 下,但是 NVIDIA GPU 不会自动这样做。
- 当且仅当使用 runc,同时用 systemd 来管理 cgroup 时会出现这个 BUG(Docker 守护进程的参数
"exec-opts": ["native.cgroupdriver=systemd"])。 - 类似地,k8s 也受此影响。
在 Docker 中复现:
- 先重启容器,用
nvidia-smi看确认 GPU 还在。 - 然后在宿主机运行
sudo systemctl daemon-reload。 - 确认容器中的 GPU 已经丢失,
nvidia-smi输出Failed to initialize NVML: Unknown Error。
(按照链接中给出的这个步骤我成功复现了问题。)
这里提供了三种解决思路:
- 创建一些符号链接。这个评论 也提到了相同的内容。
- 在宿主机和容器中都操作过了,但是没有效果,不知道如何才能成功。
- 需要使用 nvidia-ctk(见 安装文档)。
- 禁用 cgroups 并重启 docker daemon。
- 在 /etc/docker/daemon.json 中修改
"exec-opts": ["native.cgroupdriver=cgroupfs"]。 - 重启 docker,经测试可以成功。
- 在 /etc/docker/daemon.json 中修改
- 降级 docker。
2024 年 10 月 26 日:现在其他同学反映使用 native.cgroupdriver=cgroupfs 之后无法启动新的容器?
2024 年 10 月 31 日:恢复了原来的 cgroup driver,并尽可能保证服务器不用 systemctl daemon-reload。知会了所有同学,但是还是隔段时间又有 systemd 重载配置的情况发生。通过 journalctl 发现是 snapd.service 请求了重载,就将 snapd 禁用了。