NVIDIA 博客:NCCL 2.12 PXN 优化
文章总结
内容由 AI 生成
NCCL 2.12 的核心改进包括:
- PXN (PCI × NVLink): 这是一项新功能,它允许 GPU 直接通过 NVLink 和 PCI 与节点上的网卡 (NIC) 进行通信,从而绕过 CPU。这带来了更高效的数据传输和更高的带宽。
- 优化的消息聚合: PXN 使得节点上的所有 GPU 能够将它们的数据汇总到一个 GPU 上,以发送到特定目的地。这样,网络层可以将多个消息作为一个整体发送,提高了消息速率并减少了连接开销。
- 轨道优化的网络拓扑: PXN 利用 NVSwitch 连接将数据移动到与目的地位于同一网络轨道上的 GPU,避免了通过第二层主干交换机进行的效率较低的流量。
这些进步使 all2all 性能提升了两倍以上,并为复杂的 GPU 拓扑中的模型并行性提供了更大的灵活性。
虽然看上去是三项功能,但是从描述来看都是 PXN 使得它们得以实现,所以实际上主要改进还是 PXN 的引入。
PXN 对 alltoall 的改进
GPU 不是在其本地内存中为本地 NIC 发送数据准备缓冲区,而是在中间 GPU 上准备缓冲区,通过 NVLink 写入。然后它通知管理该 NIC 的 CPU 代理数据已准备好,而不是通知其自己的 CPU 代理。GPU-CPU 同步可能会稍微慢一些,因为它可能需要跨越 CPU 插槽,但数据本身仅使用 NVLink 和 PCI 交换机,确保最大带宽。
原来的 alltoall 传输前是要在发送方准备数据缓冲区的,local rank 0 如果想要发给 peer rank 3 就需要先在自己这里准备数据,然后经过多层路由传输给 peer rank 3。现在是在 local rank 3 上准备数据缓冲区(应该是 RDMA 用),local rank 0 通过 nvlink 将数据传输给 local rank 3,然后 local rank 3 发给 peer rank 3。因为后两者属于同一个 rail,所以只需要经过 L 层次的 switch,减少了路由延迟。
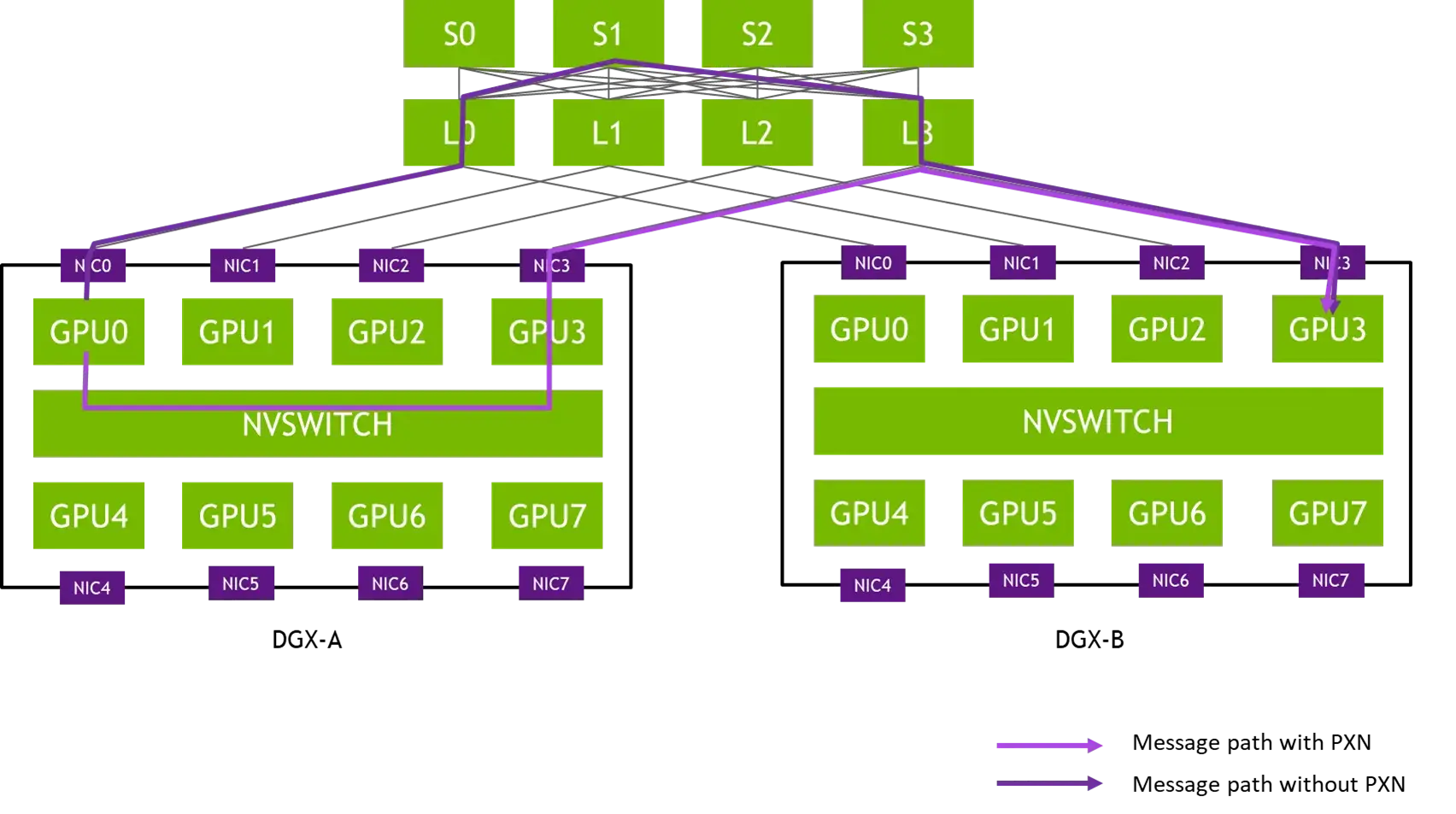
如图,深紫色的线(上面)是原来的路由方式,浅紫色的线(下面)是现在的路由方式。经由同 rail(应该指的是 local rank 相同的对端 GPU 集合)的 GPU 转发,可以避免经过 S 层,减少延迟和网络拥塞,必要的跨 rail 通信变成了经过 NVSWITCH 的 GPU0→GPU3 本地传输。
对比 DeepEP
DeepEP 有卡内和机内两重冗余的消除操作,而且用到了先机间通信再机内通信的 dispatch 方案。NCCL 2.12 也实现了两层次的转发,优化了通信链路,但是没有做冗余消除这件事(因为没有信息可以让 all_to_all 来识别冗余数据)。
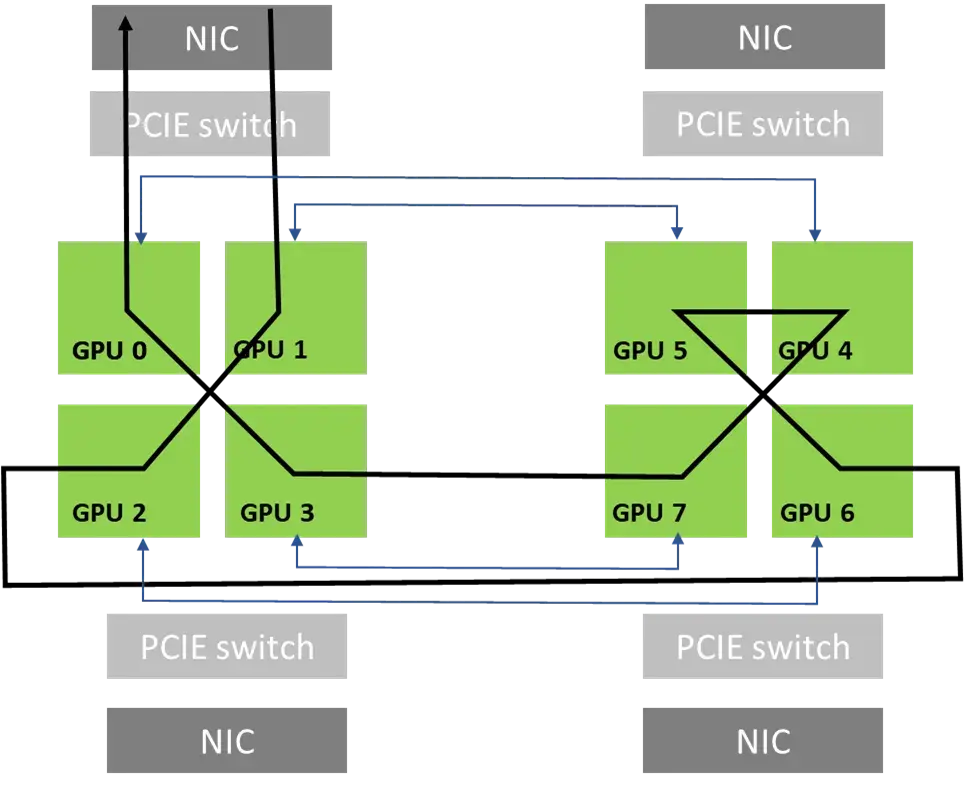
PXN 对 GPU:NIC=1:1 场景的 Ring 算法的改进
跨机 Ring 算法(比如用于 all_reduce 和 all_gather)需要每 2 个 GPU 连在同一个 NIC 上,这样可以方便组成环形。虽然 GPU:NIC=1:1 可以使用更多的网卡进行通信,总带宽更高,但却不能很好和 Ring 算法兼容,需要经过 CPU 转发(也不能简单阉割成 2:1 来用,因为 GPU 网口没有连在同一个 NIC 上)。
直观感受是要从同一个 NIC 进 node 和出 node,所以这两个 node 需要连在同一个 NIC 上。
现在 PXN 使得 GPU 可以将数据通过 NVSWITCH 传输到对应 GPU 上再通过 NIC 发送,避免了经过 CPU。