MoE Parallel Folding、ETP 和 DeepEP
DeepEP 假设了本地 node 用 NVLINK 连接的卡数为 8,因此 EP 必须在最内层。Megatron 在 MoEFlexTokenDispatcher 接入 DeepEP,也必须满足这个假设。
在 MoE Parallel Folding 下,MoE 层的 CP 消失,排在 EP 内层的只有 TP,Megatron 是如何处理 ETP > 1 的情况的?它将 routing map 展开了 tp_size 份,直接用 DeepEP 分发(这个时候使用 TP-EP 组而不是 EP 组,大小为 ep_size * tp_size),这样就满足了 DeepEP 的假设,实质上利用 DeepEP 把 TP 的通信也做了。
我认为 MoE Parallel Folding 的优势是:1. 兼容 DeepEP;2. 把 Attention 和 MoE 的 TP 数解耦;3. 为 EP 让出了 CP 的范围,使得 EP 通信组排列更局部,通信效率更高。
一般来说 MoE 层的 ETP 通信是先做 AlltoAll 再做 AllGather。因为 AllGather 会在 TP 组内形成冗余(大家都拿到一模一样的输入),所以应该只在真正需要用到之前才做 AllGather,将 AllGather 放在 AlltoAll 后可以减少 AlltoAll 的通信量(图片来自 MoE Parallel Folding 论文,上文已给出链接):
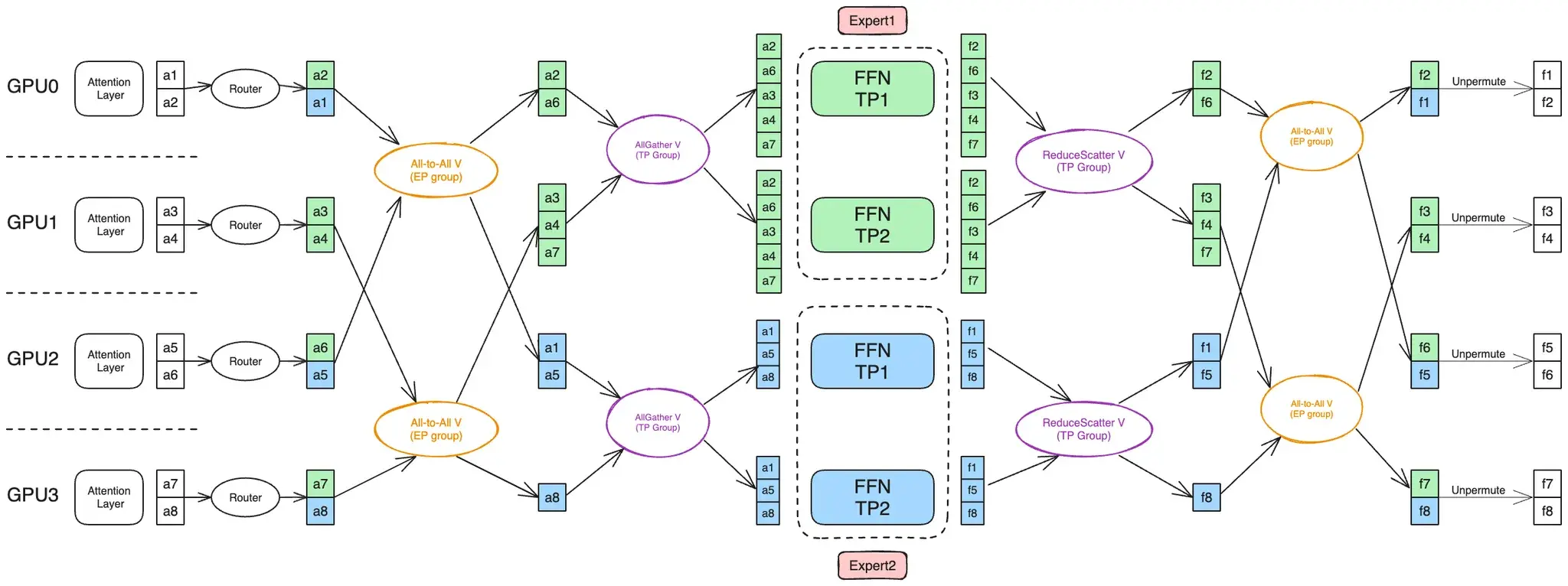
MoEFlexTokenDispatcher 有底气把 TP 交给 EP 去做,是因为 DeepEP 有去重的能力,机内 TP 冗余可以自动去除、然后通过 NVLINK 转发,等效于我们 AlltoAll 完成后 TP 组机内 AllGather。
MoEAllGatherTokenDispatcher 是直接在 ETP 组做 AllGather,见 megatron/core/transformer/moe/token_dispatcher.py#L258-L260 。
MoEAlltoAllTokenDispatcher 则是和上图一样先 AlltoAll 再 AllGather,见 megatron/core/transformer/moe/token_dispatcher.py#L650-L660 中的 dispatch_postprocess。