Megatron-LM 论文 PP 和 VPP 画法疑问
问题
见到过两种画法:一是 device 1 调度到 PP*VPP 个微批次之后继续调度,二是 device 1 调度到 PP*VPP 微批次之后就停下了。
来源 1:Megatron-LM 论文
这个是 Megatron 的论文 Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM 第 3 页 https://arxiv.org/pdf/2104.04473 ,同时显示了交错和非交错状态下 1F1B 的调度方式。
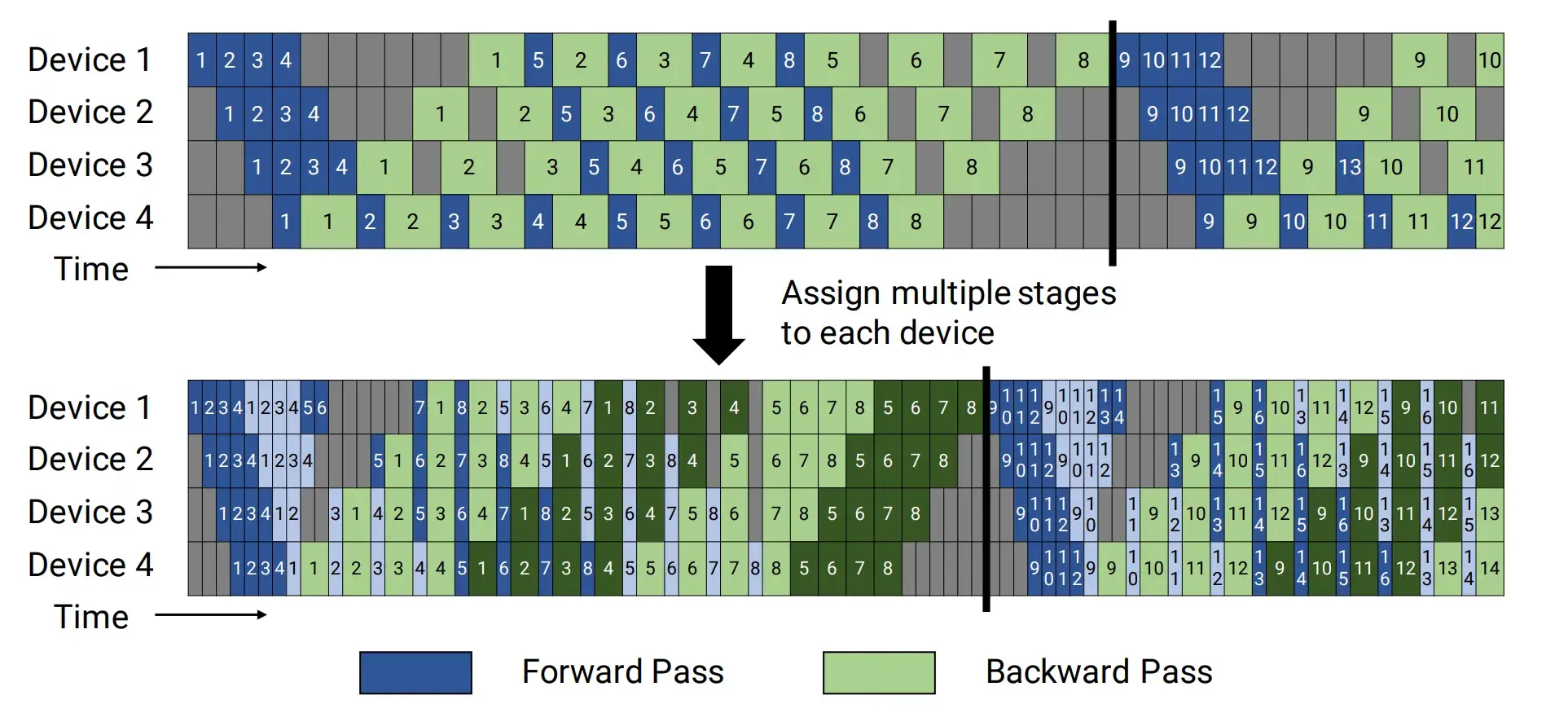
来源 2:Pangu Ultra 论文
这个是盘古的论文 Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs 第 7 页 https://arxiv.org/pdf/2504.07866 。无论是交错还是非交错 1F1B 均和 Megatron 论文画法有差异。
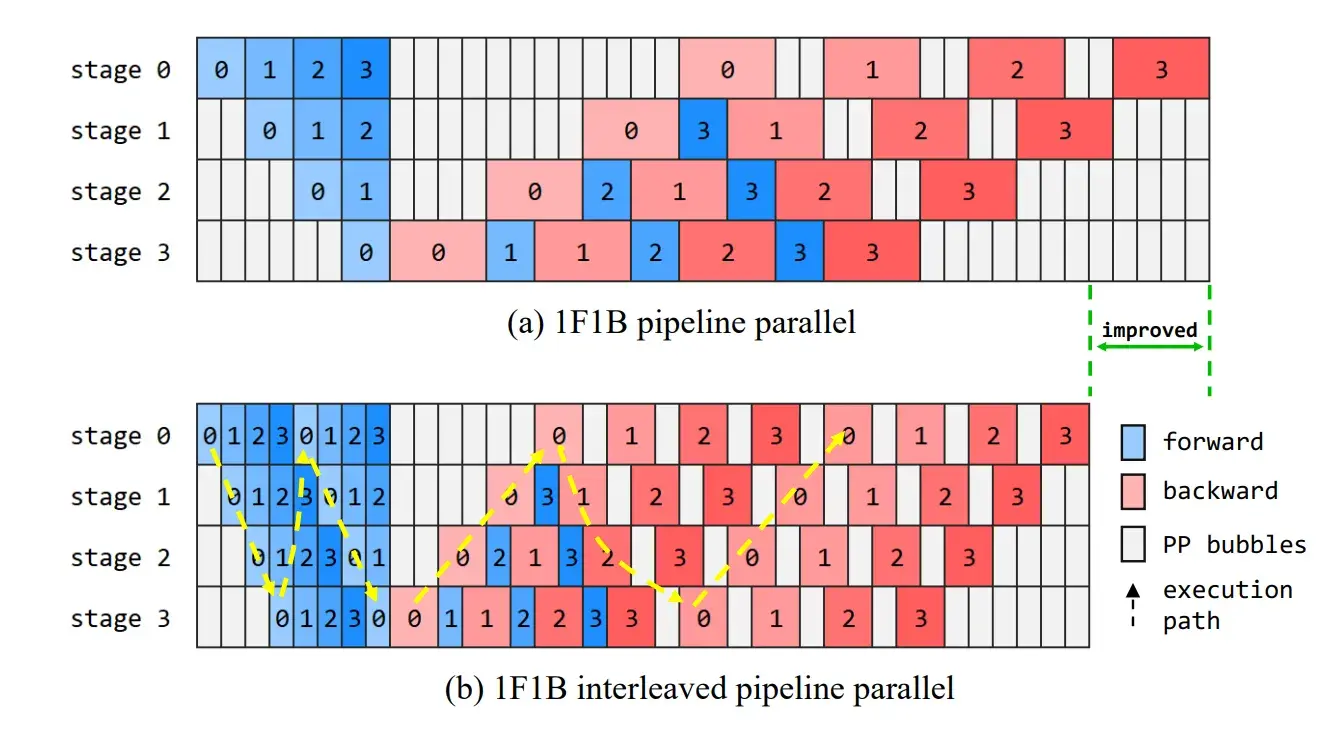
来源 3:ZeRO Bubble 论文
这个是 ZeRO bubble 论文 ZERO BUBBLE PIPELINE PARALLELISM 第 3 页 https://arxiv.org/pdf/2401.10241 ,其中的 1F1B 画法和 Megatron 论文有差异。
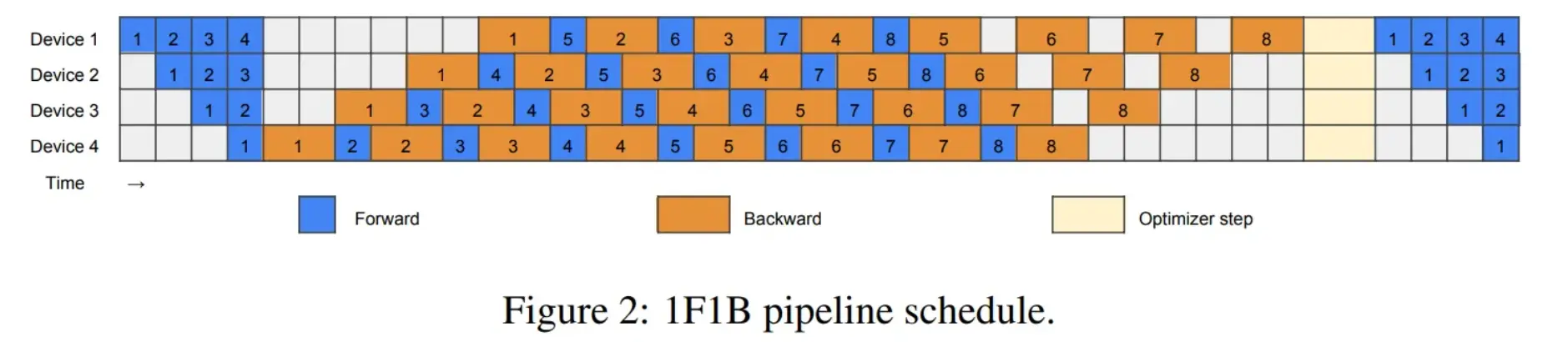
来源 4:英伟达中文博客
https://developer.nvidia.com/zh-cn/blog/1f1b-moe-a2a-computing-overlap/ 本文由小红书团队和英伟达中国一同贡献,在英文区找不到?
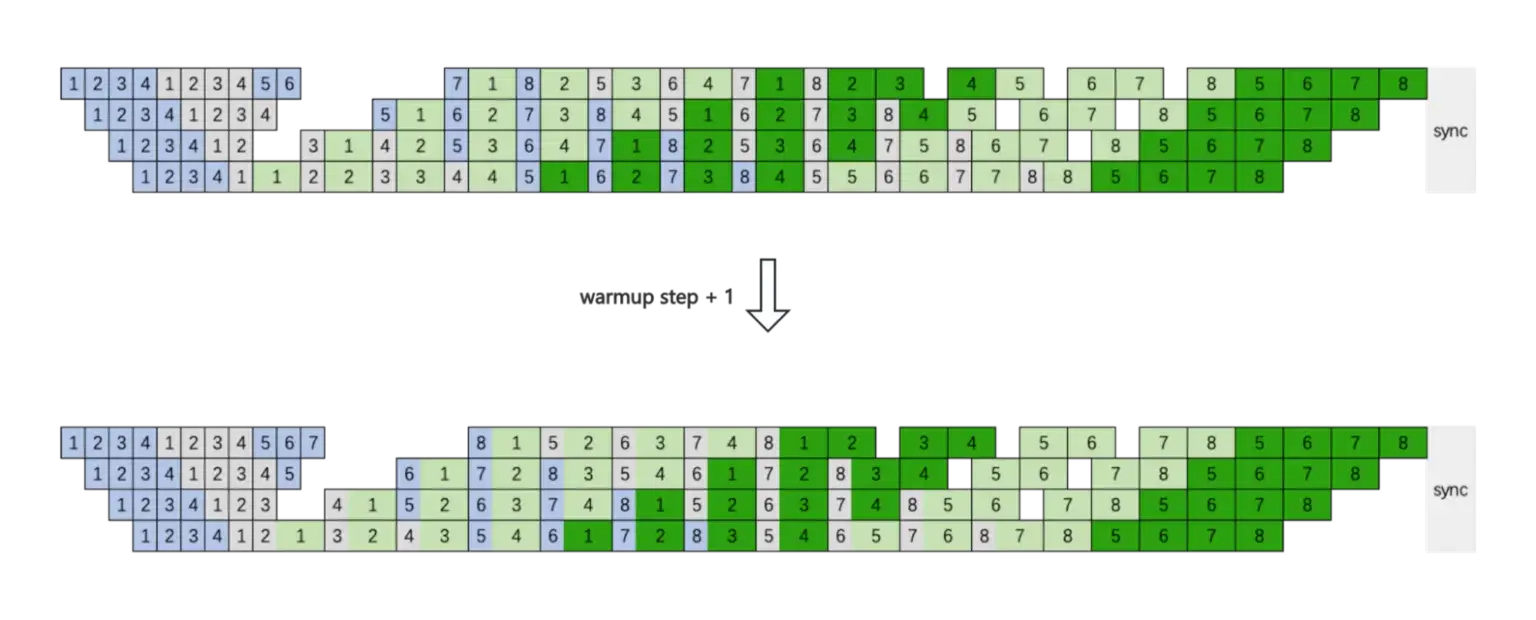
这张图表示加大 warmup 微批次数,上面的图是 baseline 的非交错 1F1B,用的是 device 1 到 PP 个微批次就停下来的画法(和 Megatron 论文不一致)。
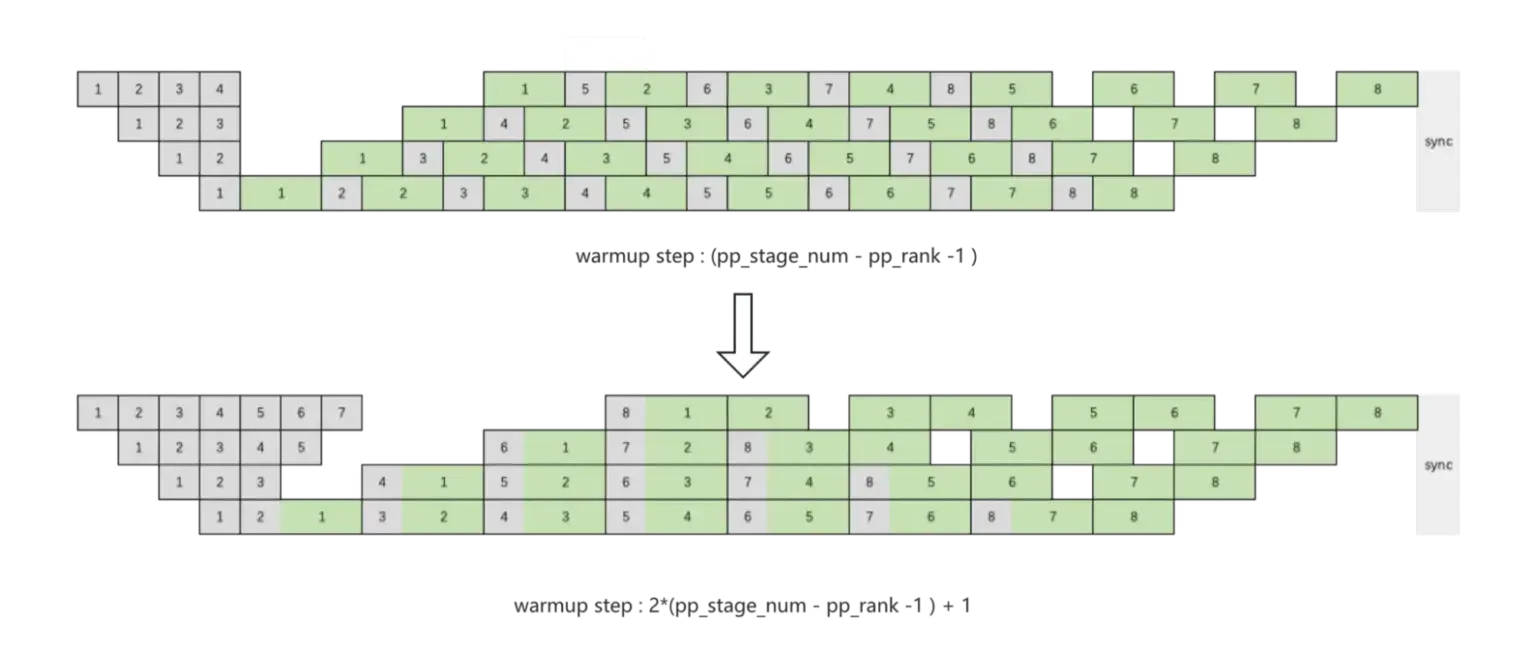
下面这张图的上图是 baseline 的交错 1F1B,用的是 device 1 到 PP 个微批次不停下的画法(和 Megatron 论文一致)。
来源 5:Megatron-LM 仓库
README
Megatron-LM 仓库的 README 也说开了 VPP 之后显存占用会变大,和自己论文的交错 1F1B 画图对应。
1F1B
- 1F1B warmup:每个 rank 循环
num_warmup_microbatches次 - 1F1B 计算 num_warmup_microbatches:每个 rank 的 warmup 数不同,和 Megatron 在论文中画的图不一致

交错 1F1B
- 交错 1F1B warmup 次数由 get_pp_rank_microbatches() 决定
- 交错 1F1B 计算 num_warmup_microbatches
 这张图来看,每个 rank 的预热阶段微批次数应该依次 -2。
这张图来看,每个 rank 的预热阶段微批次数应该依次 -2。
从以上信息来看:
- Megatron 论文给的非交错 1F1B 图不对。
- 盘古给的交错 1F1B 图不对。
- 小红书 x 英伟达博客给的图更合理一些。