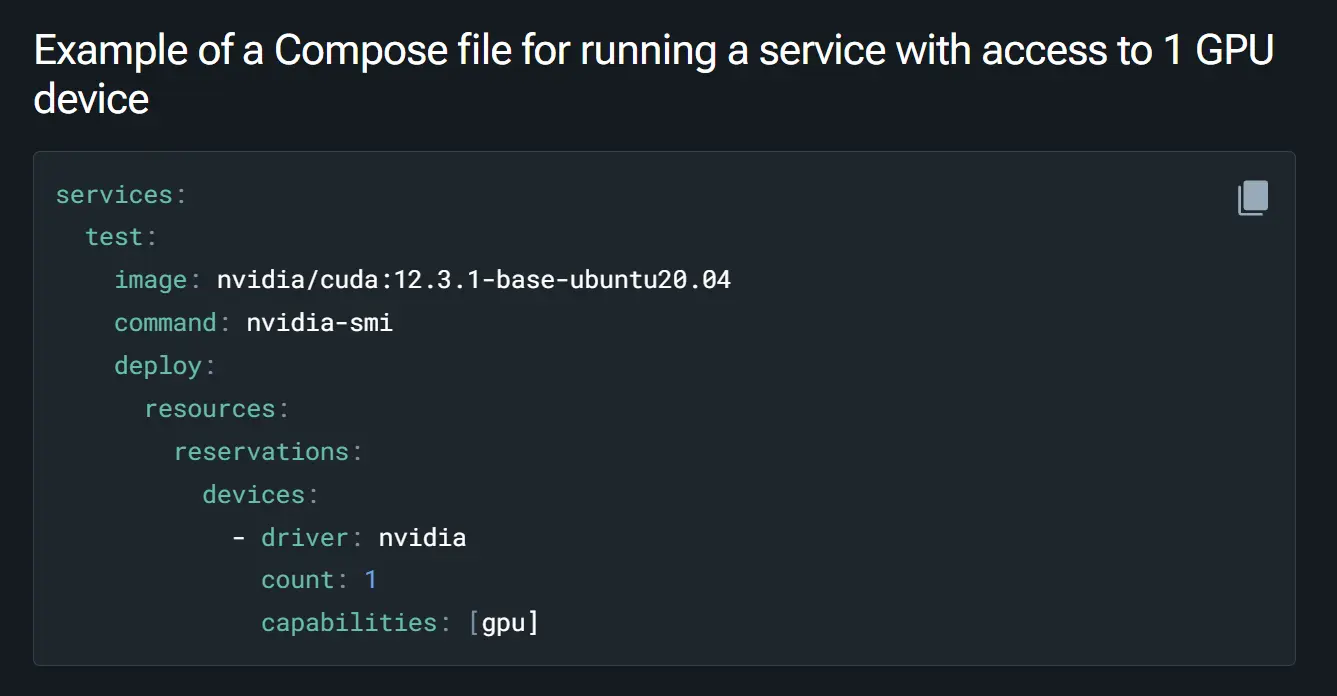
Hugo 文章摘要
说明
在我写这个文章摘要代码片段的时候,Hugo 还没有支持按照元素截取,因此 summary 是纯文本、没有格式。
现在 Hugo 已经实现了带格式的截取。目前内置实现和我实现的区别是:内置实现是按照词数截取的,直到词数满足要求就停止添加新的元素,我的实现是按照顶级元素数量截取的(以前用 Hexo 插件有这个功能,因此我实现的也是这个)。
由于 Hugo 没有开放给 html 模板足够的功能,很多数据结构有点大材小用,Hugo 内置实现远远快于用 html 模板的实现。在我电脑上测试是快了好几倍,也就是说这个文章摘要功能拖累了渲染速度。
实现
在 themes/hugo-theme-next/layouts/partials/post/body.html 的基础上修改。原本内容类似于:
{{- with .ctx -}}
{{- if or (not $.IsHome) .Params.Expand -}}
{{ .Content }}
{{- else -}}
{{ .Summary }}
{{ end }}