8. Designing concurrent code
False sharing
- Cache ping-pong
std::hardware_destructive_interference_size
还有 std::hardware_constructive_interference_size。在大多数情况下这两个值相等,而且都等于 cache line 的大小。
https://stackoverflow.com/questions/39680206/understanding-stdhardware-destructive-interference-size-and-stdhardware-cons 第一个回答的评论里面指出如果目标平台有多个,那么为了兼容性,这两个常量可能是不同的。在特定架构上这两个常量应该是相同的。
例子:矩阵计算
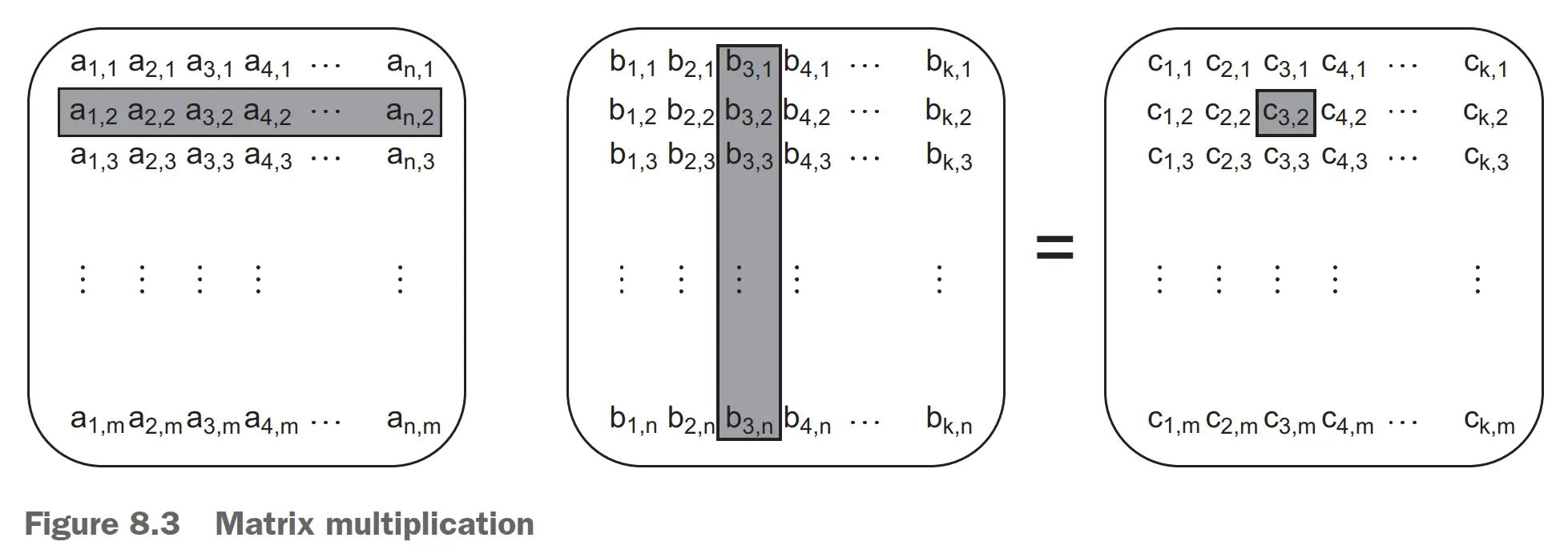
- 每个线程计算一组列。列可以先加载到当前线程,每次都读一整行,对 cache 友好。
- 每个线程计算一组行。相比于方案 1,读的 false sharing 更多,但是写操作的 false sharing 会更少。
- 分块矩阵。访问输入矩阵元素的数量减少了,同时保持计算出来的元素数相同,因而效率更高。