Python __pycache__
工作原理
https://peps.python.org/pep-3147/#python-behavior
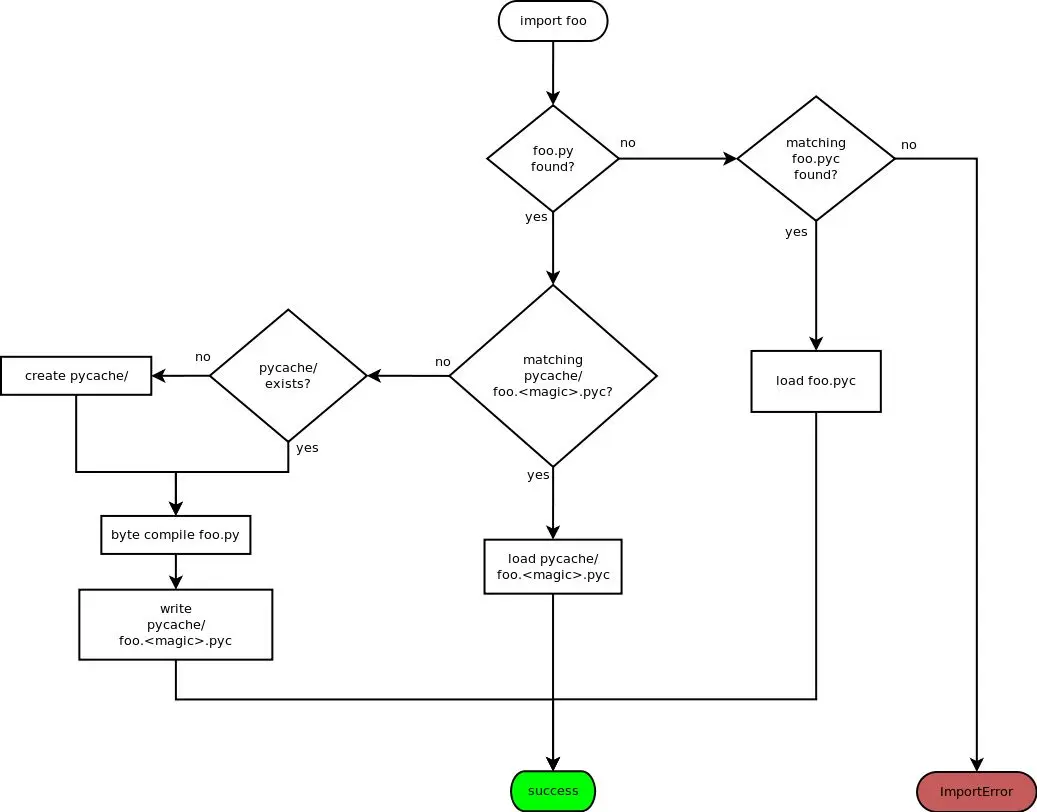
每次 import 的时候,解释器检查当前目录下的 __pycache__ 文件夹,读取和 Python 版本对应的 cache,然后读取 cache 中库的修改时间(cache 文件中记录着源码的修改时间,并不是 cache 文件本身的修改时间)。将这个时间和源码的时间比较,如果这个时间不存在,或者比源码的时间新,就加载 .pyc 而不必加载源码。
问题:在 Windows 和 WSL 上测试,解释器总是能够发现最新的源码,好像没有读取字节码一样。原因是除了时间之外,pycache 还存储了源文件的长度(验证后发现确实是这样,修改代码时既不改变文件时间又不改变长度,就能复用 cache)。
Before Python loads cached bytecode from a
.pycfile, it checks whether the cache is up-to-date with the source.pyfile. By default, Python does this by storing the source’s last-modified timestamp and size in the cache file when writing it. At runtime, the import system then validates the cache file by checking the stored metadata in the cache file against the source’s metadata.Python 3.2 引入了
__pycache__,之前是在文件旁边直接生成对应的.pyc文件(加了c后缀),而不组织在文件夹中。

