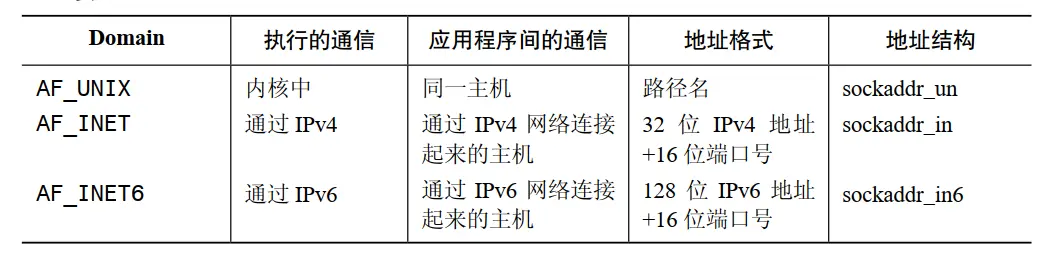
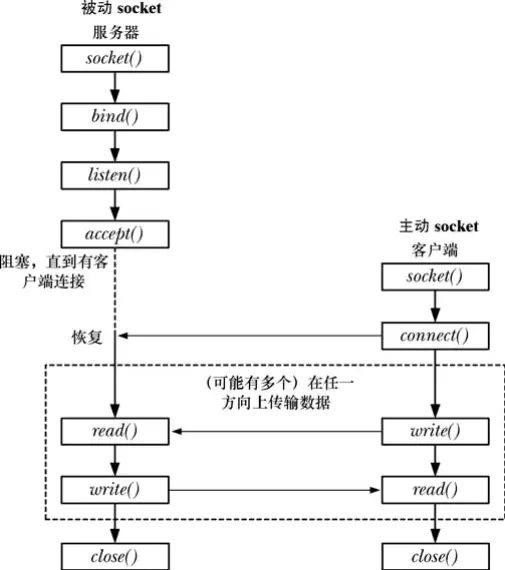
60 Socket 服务器设计
迭代型服务器和并发型服务器
迭代型服务器每次只处理一个客户端,在处理客户端请求时无法响应其他客户端;并发型服务器每次接受新的请求后,就会创建新的线程或者进程去专门处理这个请求。
inetd(Internet 超级服务器)守护进程
/etc/services 下列举着大量服务,但是每个服务器只是偶尔运行。inetd 进程通过监听一组 socket 端口并按需启动对应的服务来节省系统开销。因此 inetd 又被叫做 Internet 超级服务器。守护进程 inetd 的行为由配置文件 /etc/inetd.conf 控制(在我的 WSL(Debian)上面没有安装 inetutils-inetd,所以没有这个配置文件)。修改配置文件之后,向 inetd 发送 SIGHUP 可以要求其重载配置。
许多发行版有更加先进的 xinetd(8)。

几列数据分别是服务的名称(可以根据 /etc/services 查到服务对应的端口,理论上有些服务在不同协议下有可能使用不同端口,但是我看 /etc/services 中的服务都是 udp 和 tcp 用相同的端口号)、socket 的类型、协议、标记(要么是 wait,要么是 nowait;wait 表示在子进程运行时暂时将对应 socket 从监听列表中移除,等子进程退出后再次加入监听)、登录名(控制子进程的用户名和组名,由于 inetd 是 root 运行的,所以不控制子进程的凭据会有很大的风险)、程序位置、参数列表(图中只提供了 aegv[0])。