保存被终端转义后的文本
问题起因
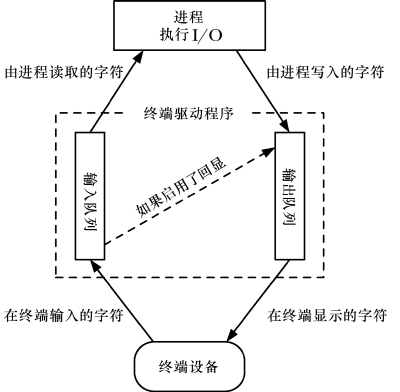
我的某个程序会自己打印 \r 和 \b 字符以在终端上起到提示效果,但是如果将内容重定向到文件,那么显示出来效果就不好。在很多阅读器中特殊字符不能被正确显示,在 VS Code 中 \r 会换行,而 \b 也不会真正起到删除的作用。
方法 1:cat 或者 less -r
假设现在文件 A.log 中包含了大量 \r 和 \b,想要阅读它可以直接将其 cat 到终端,或者使用 less -r A.log 来阅读。用 less -r 是比较推荐的,因为还能用 / 查找、用 & 过滤。
方法 2:col
如果想要真正保存一份和我们在终端看上去一样的文件,可以使用:
col -b < A.log > A1.log