CUDA by Example: Chapter 09-12
第 9 章 原子操作
You should know that atomic operations on global memory are supported only on GPUs of compute capability 1.1 or higher. Furthermore, atomic operations on shared memory require a GPU of compute capability 1.2 or higher.
指定计算能力:
nvcc -arch=sm_11
这样就指定了计算能力是 1.1,当有些指令是只有 1.1 才能编译时加这个参数可以确保编译。同时,有了更加精确的生成目标,nvcc 可以执行一些和硬件相关的优化手段,这些优化手段在更早的架构上可能没有。
但是一个硬件上不一定支持给定的计算能力。通过 -arch-ls 可以列出设备支持的计算能力:
$ nvcc -arch-ls
compute_50
compute_52
compute_53
compute_60
compute_61
compute_62
compute_70
compute_72
compute_75
compute_80
compute_86
compute_87
compute_89
compute_90
例子是直方图计算,也就是统计各个值的元素的数量。书中的例子是对随机填充生成的字符数组的计数,每个字符值不超过 256。
可以用 prop.multiProcessorCount 来查询设备有的 SM 的数量。我们实验室项目则是直接对 blocks 数量使用了一个定数,没有查询 SM 数量。
第一个直方图的尝试是用 atomicAdd 直接在全局内存上做原子加法。但是这样的性能相当差,甚至在书中所用的硬件上比 CPU 上的计算慢了好几倍。用自己的设备测试,则 CPU、全局内存原子加法、共享内存原子加法耗时分别为 182ms
、62.5ms、30ms。虽然全局内存上的原子加法开销没有那么离谱,但是也比共享内存上的加法慢了很多。
计算直方图的可以用共享内存优化,先在各个块内用原子加法计算好块中的每个元素的数量,然后一口气用原子加法加到全局内存上去。虽然计算的过程多了,使用原子加法的次数也看起来变多了,但实际上却能节省很多时间!
__global__ void histo_kernel( unsigned char *buffer,
long size,
unsigned int *histo ) {
// clear out the accumulation buffer called temp
// since we are launched with 256 threads, it is easy
// to clear that memory with one write per thread
__shared__ unsigned int temp[256];
temp[threadIdx.x] = 0;
__syncthreads();
// calculate the starting index and the offset to the next
// block that each thread will be processing
int i = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
while (i < size) {
atomicAdd( &temp[buffer[i]], 1 );
i += stride;
}
// sync the data from the above writes to shared memory
// then add the shared memory values to the values from
// the other thread blocks using global memory
// atomic adds
// same as before, since we have 256 threads, updating the
// global histogram is just one write per thread!
__syncthreads();
atomicAdd( &(histo[threadIdx.x]), temp[threadIdx.x] );
}
第 10 章 Streams
Page-Locked Host Memory
CUDA 提供了一个函数是 cudaHostAlloc,这个函数能够分配 host 端的内存。并且分配的内存是页锁定的(page-locked)或者说是固定的(pinned memory)。固定的内存不能被操作系统换出到外存,永远都存在于内存系统,因而其物理地址保持长期有效性,可以被硬件访问。CUDA 从 CPU 向 GPU 拷贝内存要使用 DMA,如果原先的内存就是页锁定的,则只会拷贝一次。如果原先的内存不是页锁定的,需要先将其拷贝到页锁定的内存上,然后拷贝到 GPU 上。malloc 创建的内存没有页锁定的性质。
结论:cudaHostAlloc 分配的页锁定的 host 内存更适合和 GPU 之间做数据交换。
However, you should resist the temptation to simply do a search-and-replace on malloc to convert every one of your calls to use
cudaHostAlloc().
缺点是分配页锁定的内存更容易 OOM,也容易影响到系统上其他的应用程序。
We suggest trying to restrict their use to memory that will be used as a source or destination in calls to
cudaMemcpy()and freeing them when they are no longer needed rather than waiting until application shutdown to release the memory.
用 cudaHostAlloc 创建的内存要用 cudaFreeHost 来释放。注意两个函数的命名规则有不一致的地方。
HANDLE_ERROR( cudaHostAlloc( (void**)&a,
size * sizeof( *a ),
cudaHostAllocDefault ) );
// ...
HANDLE_ERROR( cudaFreeHost( a ) );
Caution
我使用书中所给的测试代码发现 cudaHostAlloc 分配内存的拷贝反而更慢。将 SIZE 改小之后观察到 cudaHostAlloc 分配的内存比用 malloc 分配的稍微快了一些。可能是因为系统内存不够大,用页锁定内存反而影响性能了。
检查 CUDA 属性中的 deviceOverlap
cudaDeviceProp prop;
int whichDevice;
HANDLE_ERROR( cudaGetDevice( &whichDevice ) );
HANDLE_ERROR( cudaGetDeviceProperties( &prop, whichDevice ) );
if (!prop.deviceOverlap) {
// ...
}
这段代码检查当前设备是否具有 deviceOverlap 功能。有这个功能的设备能够同时执行 kernel 并且在 CPU 和 GPU 之间异步拷贝数据。
A GPU supporting device overlap possesses the capacity to simultaneously execute a CUDA C kernel while performing a copy between device and host memory.
书中创建了 cudaEvent_t 但是没有销毁,自己写的话还是要记得销毁。 https://stackoverflow.com/a/10943498/
为核函数调用和 cudaMemcpyAsync 指定流
cudaMemcpyAsync 要求 host 端的内存必须是 pinned memory,这和 cudaMemcpy 不强制要求内存类型不同。
cudaMemcpy 是同步的,当函数执行完成时,可以认为数据已经完成了复制。而 cudaMemcpyAsync 是异步的,只能保证它比同一个 cudaStream_t 中的后加入的任务先完成,并不能保证返回时就完成了(甚至可能函数返回时任务还没有开始)。
下面这个核函数调用也有 stream 参数(以往书中例子尖括号里都是只有两个参数,现在有 4 个),这时的核函数调用也是异步调用:
kernel<<<N/256,256,0,stream>>>( dev_a, dev_b, dev_c );
创建流是很简单的(但是记得用完要销毁):
cudaStream_t stream;
HANDLE_ERROR( cudaStreamCreate( &stream ) );
用 cudaStreamSynchronize 函数去同步一个流,也就是等待这个流上的所有操作都完成。(类似的,如果将 CUDA event 当成一个瞬间完成的低开销标记,同步一个 CUDA event 是不是也是等待这个 event 在流上的执行/标记完成呢?)
流的类型是指针而不是整数,所以将 0 赋值给流其实是指定了空指针。
使用多个流
In fact, the execution timeline can be even more favorable than this; some newer NVIDIA GPUs support simultaneous kernel execution and two memory copies, one to the device and one from the device.
先看结果:
Note
在我的电脑上,basic_single_stream.cu 和 basic_double_stream.cu 耗时 26ms,而 basic_double_stream_correct.cu 耗时 21.4ms。
书的作者所用硬件的耗时优化结果如下(和我的差不多都是节省了 20% 时间):
The new code runs in 48ms, a 21 percent improvement over our original, naïve double-stream implementation.
书中的 basic_double_stream.cu 将 chunks 拆分成了两组,偶数使用 stream0,奇数使用 stream1,但是最后的性能和使用单个流没有区别。
下图左边是错误的编码方式,右边是正确的编码方式:

由于任务是按照顺序加入到 stream 中的,而 stream 只保证同步关系,和硬件的执行无关,所以左边的写法会出现硬件中一个流的任务阻塞了另外一个流的任务的情况。毕竟严格的顺序执行并不违背同步关系。
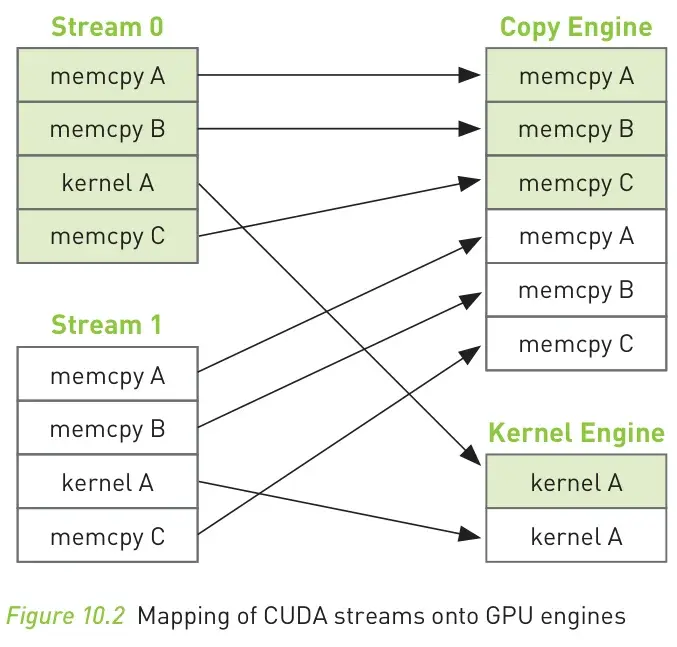
考虑左边的代码,在上图,由于前三个 cudaMemcpyAsync 都在第二个流的首个操作,即 cudaMemcpyAsync 之前,所以第二个流会等待这三个 cudaMemcpyAsync 执行完才会开始。但是第三个 cudaMemcpyAsync 是第一个流的最后一条任务,所以两个流时间上是顺序执行的,和一个流的执行时间没有区别!
如果 GPU 只支持一次执行一个拷贝和 kernel 操作,那么按照后一种交错指定任务的写法,只有流 1 数据拷贝回 CPU 的操作能够和流 2 的 kernel A 运行并行化。但是有些比较好的 GPU 支持一次执行一个 kernel 操作和多个数据拷贝操作,这会让节约的时间更多。
注意在计算完成之后还要对用到的两个流同步。(cudaStreamSynchronize)
第 11 章
零拷贝、CPU 和 GPU 之间的内存映射
查询内存映射支持:
cudaDeviceProp prop;
int whichDevice;
HANDLE_ERROR( cudaGetDevice( &whichDevice ) );
HANDLE_ERROR( cudaGetDeviceProperties( &prop, whichDevice ) );
if (prop.canMapHostMemory != 1) {
printf( "Device can not map memory.\n" );
return 0;
}
启用内存映射:
HANDLE_ERROR( cudaSetDeviceFlags( cudaDeviceMapHost ) );
在申请 host 内存时启用内存映射(注意现在用的 flag 不是 default 了,cudaHostAllocMapped 表示内存映射,cudaHostAllocWriteCombined 则是选择了 CPU 的 cache 方式,这种方式对于读少的情况有利):
HANDLE_ERROR( cudaHostAlloc( (void**)&a,
size*sizeof(float),
cudaHostAllocWriteCombined | cudaHostAllocMapped ) );
cudaHostAlloc 申请的指针总是在 CPU 内存区域的。现在启用映射之后,可以将其转换成 GPU 区域的指针,有了 GPU 区域的指针才能在 GPU 上读写:
HANDLE_ERROR( cudaHostGetDevicePointer( &dev_a, a, 0 ) );
// ^ 这个参数是 flag
内存映射有一点特殊,核函数对映射区域的修改需要同步才对 CPU 可见(因为本身 GPU 和 CPU 就是异步的),在 host 端对 GPU 同步需要调用 cudaDeviceSynchronize:
dot<<<blocksPerGrid,threadsPerBlock>>>( size, dev_a, dev_b,
dev_partial_c );
HANDLE_ERROR( cudaDeviceSynchronize() );
Caution
cudaThreadSynchronize 已经是过时的函数(书中使用),过时原因是其名称不能正确反映其功能。现在应该用 cudaDeviceSynchronize。
之前书里的 dot 计算主要做的是:
- 申请设备内存
- 将数据用
cudaMemcpy的方式拷贝到设备内存 - 调用 kernel 计算
- 用
cudaMemcpy将数据拷贝回 CPU - 完成其他处理
- 释放资源
为什么这个过程不需要同步呢?因为 cudaMemcpy 是在 kernel 之后发起的,虽然 kernel 的执行是异步的,但是 cudaMemcpy 的执行是同步的。CPU 要等待 cudaMemcpy,而 cudaMemcpy 要等待 kernel,所以达成了同步关系。
使用 cudaMemcpyAsync 还要注意同步其他流。这个时候也达成了同步。
但是这里的新例子中 kernel 之后没有天然的同步措施,所以要使用 cudaDeviceSynchronize 对设备同步,保证 CPU 能够看到正确的结果。
什么时候用内存映射?当典型的只拷贝一次到设备内存,计算完成之后就拷贝回去时,这种方法比较高效。但是要注意:如果对内存区域读写次数很多,这种方法反而更慢;映射内存必须是页锁定内存,给系统内存会带来负担。
In cases where inputs and outputs are used exactly once, we will even see a performance enhancement when using zero-copy memory with a discrete GPU.
书中还有提到在核显的时候用内存映射肯定是有提升的。(但是核显一般不是 N 卡)
多 GPU 计算
首先是要用 cudaGetDeviceCount 查询 GPU 数量。
然后每个 GPU 设备要专门用一个 CPU 线程来控制。可能如果不用多个线程,cudaSetDevice 就会冲突,无法使用多个设备。
CUTThread thread = start_thread( routine, &(data[0]) );
routine( &(data[1]) );
end_thread( thread );
这里的例子中 routine 是一个函数,而 start_thread 和 end_thread 都是本书给出的,实际上是调用了 pthread 库。
Portable Pinned Memory
Caution
Once you have set the device on a particular thread, you cannot call cudaSetDevice() again, even if you pass the same device identifier.
Note
如果不使用 cudaSetDevice,那么就用默认设备 0。根据书上所说,一旦对当前线程设置了设备就不能再次设置,否则会出错。但实际上我对同一个设备调用多次也没有出错。
本章并没有马上申请映射内存,而是使用了很早之前讲过的先复制到 GPU 计算完成再复制到 CPU 的方案。这是因为本章涉及了多设备,同时也涉及了多线程。使用一般方法申请的 pinned memory 只是对于作为资源申请者的那一个线程是页锁定的,对于其他线程来说是非页锁定的,这会造成在使用 cudaMemcpy 时不必要的拷贝开销。要想申请 portable pinned memory,也就是对所有线程可见,需要额外添加 cudaHostAllocPortable 标志:
HANDLE_ERROR( cudaHostAlloc( (void**)&b, N*sizeof(float),
cudaHostAllocWriteCombined |
cudaHostAllocPortable |
cudaHostAllocMapped ) );
第 12 章 CUDA 工具
数学库
CUDA Toolkit 包含这两个库:CUFFT 和 CUBLAS。
CUFFT:快速傅里叶变换库。
CUBLAS:基本线性代数子程序库。
This library, named CUBLAS, is also freely available and supports a large subset of the full BLAS package.(BLAS 是用 FORTRAN 实现的库。)
其他
GPU Computing SDK:在 CUDA driver 和 CUDA Toolkit 之外。其中也附有一些示例代码,这些代码都是学习用,并不是 SOTA。
NVIDIA Performance Primitives (NPP):主要用于图形和视频处理。
调试工具:cuda-gdb 和 cuda-memcheck(感觉有点像 valgrind 在 GPU 上的改造?)。NVIDIA Parallel Nsight 是最开始在 Windows 上支持 CUDA 调试的工具。
Profiler:CUDA Visual Profiler。