(CppCon 2023) C++ Memory Model - from C++11 to C++23 - Alex Dathskovsky
视频链接 https://www.youtube.com/watch?v=SVEYNEWZLo4
不要用 Volatile 来同步
Note
顺带一提:C++20 中,有不少和 volatile 相关的操作都已经被标记为过时。详见 https://en.cppreference.com/w/cpp/language/cv
#include <tuple>
int main() {
volatile int x = 0;
//! C++20
//! 1.1 函数参数不能用 volatile 类型
// auto f1 = [](volatile int) {};
//! 1.2 函数返回值不能 volatile 类型
// auto f2 = []() -> volatile int { return 0; };
// int y = (x = 6);
//! 2 自增、自减运算符不能在 volatile 变量上操作
// x++;
//! 3. 结构化绑定不能用 volatile
// auto volatile [a, b] = std::tuple{1, 3};
//! 4. 不能基于 volatile 变量连续赋值,除非是在不评估的环境中
//! 错误
// int z = (x = 5);
//! 会有 -Wunevaluated-expression 警告,正确但是不推荐
using T = decltype((x = 5));
}
可以用来同步的机制:
- 汇编级别的内存屏障指令(见下方图片)
- 原子变量和锁

Memory Barriers
Acquire / Release 语义:Read-Acquire 可以构成下文内容不超过当前 acquire 屏障的保证;而 Write-Release 可以构成上文内容不超过当前 release 屏障的保证。两者结合起来可以构成 full barrier,使得两个线程可以达成同步关系。

原子读写的代价
load
在 x86 系统上,对 32 位数据的原子加载只是一次普通的加载。观察 https://godbolt.org/z/1Erq1Ters 中的汇编,没有特殊的指令被使用。
std::atomic<int> a(0);
int b = a.load();
但是在其他系统上,这样的操作可能代价很高。
store
在 x86 上对 32 位数据的原子写入要使用 xchg 指令,它有一个 full barrier。
C++ Concurrency Support
std::thread and std::jthread
std::jthread 是在 C++20 才引入的对 std::thread 的封装。它在析构时自动 join,而且包含一个 std::stop_source(C++20)来控制结束。这个 std::stop_source 和 std::stop_token(C++20)关联,从而可以让线程自行检查标志并停止。
#include <cstdio>
#include <thread>
using namespace std::chrono_literals;
int main() {
auto t = std::jthread([](std::stop_token token) {
std::atomic<bool> flag = false;
std::stop_callback callback(token, [&flag] { flag = true; });
// Run, until stop is requested:
while (!flag) {
std::this_thread::sleep_for(1s);
printf("tttt\n");
}
});
std::this_thread::sleep_for(3s);
t.request_stop(); // runs any associated callbacks on this thread
}
上面的代码虽然没有给 std::jthread 传递 lambda 以外的参数,而且 lambda 需要一个 std::stop_token 参数才能启动,但 std::jthread 会将和自己关联的 std::stop_source 上的 std::stop_token 传给 lambda。我们可以直接用 token.stop_requested() 来检查是否应该停止,也可以创建一个 std::stop_callback。
还可以用 std::condition_variable_any(C++11)来配合 std::stop_token。和 std::condition_variable 只在 std::unique_lock 上工作不同,前者可以在任何满足 BasicLockable 条件的锁上工作(详见前面的链接)。在 C++20 中,std::condition_variable_any 有一个新增的成员方法:
template< class Lock, class Predicate >
bool wait( Lock& lock, std::stop_token stoken, Predicate pred );
一般的条件变量是在被通知(notify)时唤醒,然后 pred 是用来预防假唤醒的。这个有了 std::stop_token 参数的方法会将 token 的停止标记视为通知的一种,即多了一种通知条件变量的手段。这相当于我们创建了 std::stop_callback,并在其中对条件变量进行 notify。
thread_local 关键字(C++11)
Caution
不要将 thread_local 变量的地址或者引用传给其他线程。其他线程应该直接操作它们可见的线程本地变量,如果操作传来的指针,读写将会操作于同一个变量上。
std::atomic<T>
模板类 std::atomic<std::shared_ptr<T>> 在 C++20 提供,但是它并不是无锁的。
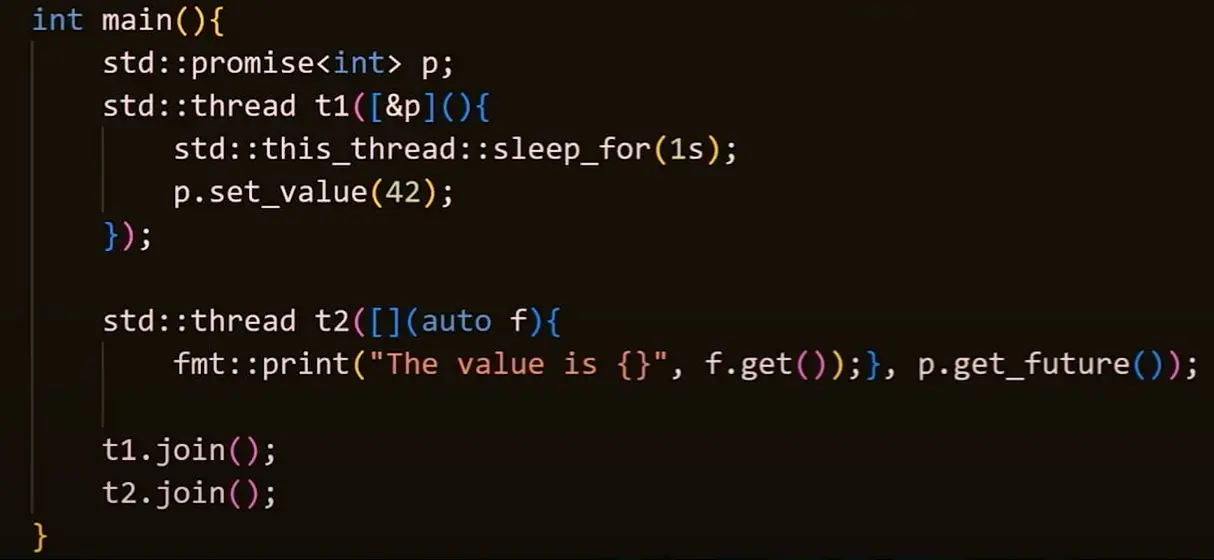
std::future 和 std::promise
可以从 std::future 上获取想要的值(值还没产生就会阻塞;但也可以指定超时时间),而 std::promise 可以用来产生 std::future。
一些有锁对象和相关的操作
std::mutexstd::condition_variablestd::lock_guard/std::scoped_lock/std::unique_lock:std::scoped_lock是 C++17 引入的、std::lock_guard的上位替代。std::counting_semaphore/std::binary_semaphore:都是 C++20 引入std::latch/std::barrier:前者只能用一次,后者可以反复使用。每次调用就让计数减少 1,然后让当前线程阻塞直到计数归零。
https://stackoverflow.com/a/60172828/
RAII 锁定函数的选择:
lock_guardif you need to lock exactly 1 mutex for an entire scope.scoped_lockif you need to lock a number of mutexes that is not exactly 1.unique_lockif you need to unlock within the scope of the block (which includes use with acondition_variable).
其他我因为比较懒所以没有打字说明的锁:

std::call_one 和 std::once_flag
https://en.cppreference.com/w/cpp/thread/call_once
它们能保证函数只被调用一次,可以用来安全地初始化共享资源。
C++ Atomic Memory Order
// C++20
enum class memory_order : /* unspecified */ {
relaxed, consume, acquire, release, acq_rel, seq_cst
};
inline constexpr memory_order memory_order_relaxed = memory_order::relaxed;
inline constexpr memory_order memory_order_consume = memory_order::consume;
inline constexpr memory_order memory_order_acquire = memory_order::acquire;
inline constexpr memory_order memory_order_release = memory_order::release;
inline constexpr memory_order memory_order_acq_rel = memory_order::acq_rel;
inline constexpr memory_order memory_order_seq_cst = memory_order::seq_cst;
不同内存序的含义:
- relaxed:没有同步要求,只保证操作是原子的。
- acquire:本线程在此操作后的读写不能重排到此次读之前。
- release:本线程在此操作前的读写不能重排到此次写之后。
- acq_rel:用来修饰一个 read-modify-write 操作,No memory reads or writes in the current thread can be reordered before the load, nor after the store. 等于是在一个读写组合的操作中,根据当前是读还是写,提供不同的内存序(acquire 或者 release)。
- consume:和 release 差不多,但是只影响有数据依赖关系的变量的读写。比 acquire 更加宽松。(cppreference:On most platforms, this affects compiler optimizations only.)
- seq_cst:默认的原子内存序,提供顺序一致性(sequentially consistent)保证,这是最严格的同步要求。如果当前操作是读,则有 acquire 语义;如果是写,则有 release 语义;如果是 read-modify-write,则是 acq_rel 语义。同时,还要加上一个”所有线程对变量修改的观察的顺序一致“的额外约束。
可以用 std::atomic_thread_fence (在全局名字空间也有这个函数)来提供内存屏障,这两个屏障达成了同步关系,如果在执行时 release 方的操作先于 acquire 方,那么 release 方在屏障之前的所有操作对 acquire 方都是可见的。这个时候,如图 r2 的值就应该是 42。由于已经显式使用了内存屏障,上面的原子变量可以用 relaxed (无同步要求)的内存序要求来读写。

以上例子也可以去掉内存屏障,因为我们可以给原子操作提供带有同步关系的内存序要求:

如果不传递内存序参数,ready.store 和 ready.load 就会使用顺序一致性的同步要求,对于这个场景来说性能会下降。
用原子操作实现简单的 Spinlock
视频里面给的例子是 std::atomic<bool>。(实际上 std::atomic_flag 也可以,而且写起来更简单,只是接口有变化。)
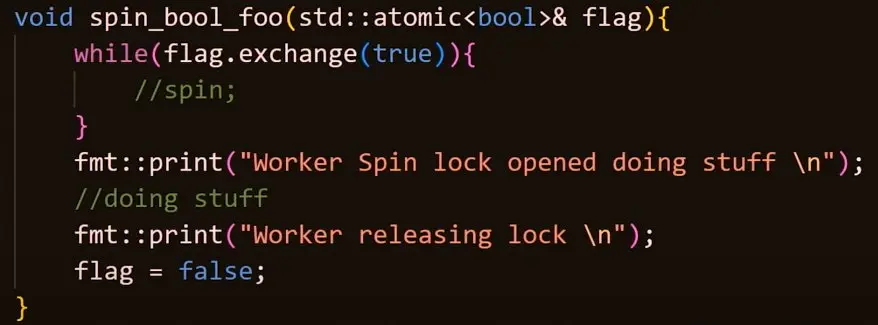
这个自旋锁应该也可以用 compare_exchange_weak 来实现。 compare_exchange 在 cppreference 的网页上有代码示例来实现无锁链表,也可以改造成实现自旋锁。
compare_exchange_* 系列函数参数的解释
compare_exchange_* 系列函数的第一个参数(expected)是引用类型,第二个参数(desired)是值类型。如果第一个参数和当前原子变量中存储的值相等,则将第二个参数赋给原子变量;否则,将原子变量中的值赋值给 expected。在这个例子中,expected 永远都是 false,所以失败之后我们要重新给 expected 赋值。
对于第三个、第四个参数,cppreference 给了一张表:
| Overloads | Read‑modify‑write Memory Model | Load Operation Memory Model |
|---|---|---|
| (1,2,5,6) | success | failure |
| (3,4,7,8) | order | 🟢 std::memory_order_acquire if order is std::memory_order_acq_rel 🔵 std::memory_order_relaxed if order is std::memory_order_release 🟠 otherwise order |
其中第二行(1,2,5,6)就是给 compare_exchange_* 系列函数传递两个内存序参数,即 success 和 failure 时候的重载;第三行(3,4,7,8)是只传递一个内存序参数时候的重载(什么都不传则有默认参数:std::memory_order_seq_cst)。
cppreference 还给了一个很好的用原子操作实现的无锁链表的例子。在那个例子中,如果操作失败,new_node->next 就是最新的 head 值,因而不需要在 while 的循环体中对 expected 参数重新赋值。由于我们在加载 expected 的时候是在本线程进行的,变量也不需要共享,所以用双内存序参数的版本,第二个参数指定 std::memory_order_relaxed,效率会更高(就像上面写的那样)。
compare_exchange_weak 和 compare_exchange_strong 的区别
cppreference 同时指出:compare_exchange_weak 是允许自发失败(acts as if *this != expected even if they are equal)的,而在某些平台上,循环中的 compare_exchange_weak 比循环中的 compare_exchange_strong 效率更高。如果用 compare_exchange_weak 需要循环,而 compare_exchange_strong 不需要(因为它不会自发失败),这个时候一般选用 compare_exchange_strong,除非类型 T 的不同位表示对应于同一个含义(比如浮点数的 NaN,或者有 trap bits,或者 C++20 之前的 padding bits,内置整数不需要考虑这些情况),这一段话在 cppreference 页面的 notes 里,最好读一下原文。 https://stackoverflow.com/a/6725981/ 给出的 trap representation 的例子是 signaling NaNs。
Casey 的回答 给了一个比较好的例子(第二个代码块疑似有 ! 漏打的 typo),可以在多个线程之间用 compare_exchange_strong 来决出功能的执行者,后来的线程就走另外一个分支。这个时候如果用 compare_exchange_weak 来做,就需要循环。