9. Advanced thread management
线程池
实现可以 submit 任务并获取 future 的线程池
有了 std::future 就能对提交的任务做等待。
线程池初始化时就创建指定数量的工作线程,每个线程的任务就是在循环中从线程安全队列上获取任务并运行。每个任务的类型是 std::packaged_task<result_type()> task,每次有工作要提交都会包装到 std::packaged_task,工作的提交者因而可以获取 std::future。
由于 C++23 才引入 std::move_only_function<>,书上实现了一个简单的替代。
修复 quicksort 工作线程的死锁
书上给了一个 quicksort 的例子,指出划分完成时,本线程先递归做完 new_higher 段的工作,再去等待 new_lower 段的工作的 future。这个实现中线程池中工作线程数量是固定的,如果所有工作线程都需要等待 future,那么就没有剩余的工作线程去真正推进任务了!有限线程数 + 线程等待尚未排队的任务 = 死锁。
解决方案是让线程在等待期间不要休眠,而是主动处理其他任务:
while (new_lower.wait_for(std::chrono::seconds(0)) == std::future_status::timeout) {
pool.run_pending_task();
}
为此,需要实现 run_pending_task(),它开放了线程池外执行线程池任务队列中任务的接口,避免其他线程做无意义的等待。
void thread_pool::run_pending_task() {
function_wrapper task;
if (work_queue.try_pop(task)) {
task();
} else {
std::this_thread::yield();
}
}
用本地队列减少单一全局队列负担
为每个工作线程创建一个本地队列:
class thread_pool {
threadsafe_queue<function_wrapper> pool_work_queue;
typedef std::queue<function_wrapper> local_queue_type;
static thread_local std::unique_ptr<local_queue_type> local_work_queue;
void worker_thread() {
local_work_queue.reset(new local_queue_type);
while (!done) {
run_pending_task();
}
}
// ...
};
类型选择 std::unique_ptr<local_queue_type>,可以避免为非工作线程创建队列,减少不必要的开销。因为本地队列只由线程本身访问,所以不需要做同步。
现在,每次执行任务时(run_pending_task),先检查是否存在本地队列(如果存在说明是工作线程),若存在则从其中获取任务,不存在本地队列或者没能获取到任务时从全局队列上获取任务。之所以要“是否存在本地队列”,是因为 run_pending_task() 这个接口也开放给了线程池外面,使得其他线程可以协助处理线程池内的任务。
函数 submit() 也要做修改,现在如果有本地队列,就优先将任务添加到本地队列上面去。这会带来问题:如果 submit() 不修改,那么没有任务会被加入到线程本地队列中去,这个队列形同虚设;如果 submit() 修改了,那么递归任务容易遇到子任务堆积的情况。这个问题在接下来被解决。
工作窃取
有些任务是递归进行的,比如书上的 quicksort 并行实现。如果工作线程使用本地队列,那么可能会出现一个线程堆积大量任务,其他线程不能处理任务的情况。
工作窃取允许线程在本地和全局队列上均无任务时,从别的线程的本地队列中窃取任务。一方面是要保证线程安全,可以用 mutex 保护;另一方面是尽量避免和本地队列的所有者发生冲突,因此可以把 queue 改成 deque,队列所有者在 front 端操作,任务窃取者从 back 端操作。执行工作的逻辑变成:
void run_pending_task() {
task_type task;
if (pop_task_from_local_queue(task) ||
pop_task_from_pool_queue(task) ||
pop_task_from_other_thread_queue(task)) {
task();
} else {
std::this_thread::yield();
}
}
和书里给的 hazard pointer 的实现类似,thread_pool 类包含一个工作队列数组,这样每个线程就能看到其他所有工作线程的工作队列并尝试在上面窃取工作。窃取工作的代码如下:
bool pop_task_from_other_thread_queue(task_type& task) {
for (unsigned i = 0; i < queues.size(); ++i) {
unsigned const index = (my_index + i + 1) % queues.size();
if (queues[index]->try_steal(task)) {
return true;
}
}
return false;
}
每个线程从 i + 1 的位置开始窃取工作,这样可以防止窃取工作时总是从 0 号线程的工作队列开始,减少了竞争(contention),同时使得工作分布得更加均匀。
可中断线程
手动添加中断点实现可中断的线程
每个工作线程关联一个 token / flag,主动适时调用 interruption_point() 检查是否需要中断,这和 pthread 库里面用 pthread_testcancel() 主动提供取消点一样(尽管许多系统调用都是取消点)。
书上将这个 flag 放在了 thread_local 变量里面,但是我觉得可以放在 thread 的栈里面(在 p.set_value 的前面),这样可以避免不是由 interruptible_thread 创建的线程也承担一个线程本地 flag 的存储开销。
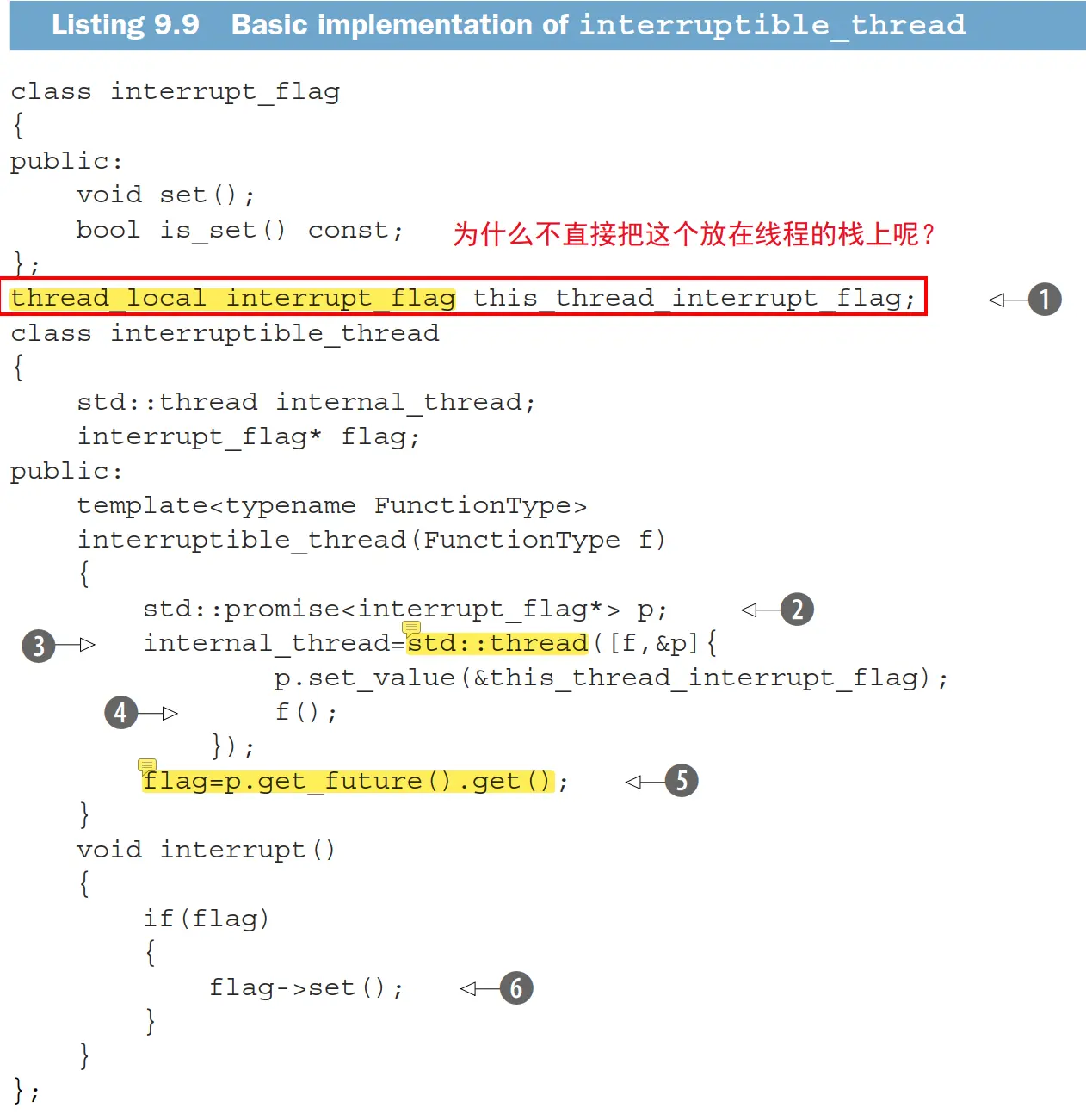
interruption_point() 的实现是:
void interruption_point() {
if (this_thread_interrupt_flag.is_set()) {
throw thread_interrupted();
}
}
这个异常谁来处理呢?不处理的话 C++ 运行时会调用 std::terminate。我个人认为在上图中的第 ③ 步,创建 internal_thread 的 lambda 中就可以对这个异常做捕获。书上把异常处理放在了比较后面的地方。
书上也没有处理线程的 join 和 detach,因此最好还是使用 C++20 加入的 std::jthread,除了能自动 join 之外,还能使用配套的 stop_token。
The destructor of
jthreadcallsrequest_stop()andjoin().(如果 joinable 才会调用这两个函数。)
中断阻塞等待
线程如果有些调用是阻塞的,那么可能一直休眠下去,就不会时不时调用 interruption_point() 了,这导致线程无法被中断。为此,所有阻塞等待需要替换成一个适时调用 interruptible_wait() 的等待方式,书中将其命名为 interruptible_wait()。
std::condition_variable

上面实现的错误原因有:
- 没有用 RAII 处理异常。
- 数据竞争:如果在注册环境变量的通知之前,就有其他线程发起了通知,那么本线程会错过这一次通知,并且在
cv.wait(lk)上永远阻塞下去。这个和 TLPI 书中解释为什么sigwaitinfo不能被sigprocmask+pause取代一样。
为了处理异常问题,书上提供了一个在析构时调用 clear_condition_variable 的 guard 类。为了处理数据竞争问题,书上将无限等待改成了只等待最多 1ms。
void interruptible_wait(std::condition_variable& cv, std::unique_lock<std::mutex>& lk) {
interruption_point();
this_thread_interrupt_flag.set_condition_variable(cv);
interrupt_flag::clear_cv_on_destruct guard;
interruption_point();
cv.wait_for(lk, std::chrono::milliseconds(1));
interruption_point();
}
其他线程如果想要中断当前线程,不仅要设置中断 flag,还要对线程当前正在等待的条件变量做通知(调用 notify_all())。因此每次工作线程要在某个条件变量上做等待前,都要将要等待的条件变量先关联到自己的 flag 上,以便其他线程发起通知。工作线程关联和解除关联条件变量的同时,其他线程可能会通过 flag 发起对关联条件变量的通知,因此需要增加一个 mutex 来防止数据竞争。最后这个 flag 类型的被设计为包含以下数据:
class interrupt_flag {
std::atomic<bool> flag;
std::condition_variable* thread_cond;
std::mutex set_clear_mutex;
};
std::condition_variable_any
上一小节是使用 std::condition_variable& + std::unique_lock<std::mutex>& 来实现的等待,书上接下来讲可以用 std::condition_variable_any& + Lockable& 实现等待,过程是差不多的。
书上还提到了既然现在可以在 std::condition_variable_any 上调用 wait,那么可以写一个包装了很多逻辑的 custom_lock 类型,它在 lock() 和 unlock() 的多个环节执行等价的操作。我个人觉得这样做反而更加复杂了,代码也不好阅读。
改写其他阻塞等待
其他阻塞等待也要相应地改成在循环中等待一段时间之后唤醒检查条件是否满足,比如对于 std::future 的等待:
template<typename T>
void interruptible_wait(std::future<T>& uf) {
while (!this_thread_interrupt_flag.is_set()) {
if (uf.wait_for(std::chrono::milliseconds(1)) == std::future_status::ready)
break;
}
interruption_point();
}
异常处理
之前在实现可中断线程的时候,interruption_point() 在发现中断的时候会抛出异常,如果这个异常不被处理,那么 std::terminate 会导致程序终止。可以通过包装用户提供的启动函数来处理异常:
internal_thread = std::thread([f, &p] {
p.set_value(&this_thread_interrupt_flag);
try {
f();
} catch (thread_interrupted const&) {
// TODO: store the exception in future
}
});
这样无论如何都不会有未处理的异常。在异常被捕获后我们可以为 future 设置好异常信息。
此外,工作函数 f() 内部也可以对中断异常做检查,并做好善后工作。
在程序退出时中断后台线程
以下为书中内容的一部分的摘录:
int main() {
start_background_processing();
process_gui_until_exit();
std::unique_lock<std::mutex> lk(config_mutex);
for (unsigned i = 0; i < background_threads.size(); ++i) {
background_threads[i].interrupt();
}
for (unsigned i = 0; i < background_threads.size(); ++i) {
background_threads[i].join();
}
}
这其实也是 std::jthread 的行为,它在退出时检查线程是否 joinable,若是则调用 request_stop() 和 join()。