5.1 libstdc++ 对共享指针原子操作的支持
引言
这篇笔记是承接 CppCon 2023 Lock-free Atomic Shared Pointers Without a Split Reference Count 和 内存模型基础、标准原子类型、自旋锁 来写的。
C++20 有 std::atomic<std::shared_ptr> 和 std::atomic<std::weak_ptr> 的偏特化,之前连这两个偏特化都没有,因而会编译错误(std::atomic requires a trivially copyable type),只能使用对共享指针提供的原子操作自由函数(std::atomic_*)。但是这样的类型并不是无锁的,可以通过 is_lock_free() 的返回值看出来,见 https://godbolt.org/z/b5P84jM9f 。根据 Daniel1 的幻灯片,MSVC 和 libstdc++ 中这两个类型都是有锁;根据我的查证,libc++ 截至 2025 年 1 月 5 日还没有实现这两个偏特化。
既然知道有锁了,libstdc++ 是怎么实现共享指针原子变量的线程安全访问的呢?
原子操作自由函数
C++20 之前原子操作自由函数对 std::shared_ptr<T> 的支持可见 atomic_load_explicit 和 _Sp_locker,它对指针值做 hash,得到互斥量池里的一个下标,从而获取一个 __gnu_cxx::__mutex 的引用。可以参考 以下代码。
// shared_ptr.cc
#include "mutex_pool.h"
namespace __gnu_internal _GLIBCXX_VISIBILITY(hidden)
{
/* Returns different instances of __mutex depending on the passed index
* in order to limit contention.
*/
__gnu_cxx::__mutex&
get_mutex(unsigned char i)
{
#ifdef _GLIBCXX_CAN_ALIGNAS_DESTRUCTIVE_SIZE
// Increase alignment to put each lock on a separate cache line.
struct alignas(__GCC_DESTRUCTIVE_SIZE) M : __gnu_cxx::__mutex { };
#else
using M = __gnu_cxx::__mutex;
#endif
// Use a static buffer, so that the mutexes are not destructed
// before potential users (or at all)
static __attribute__ ((aligned(__alignof__(M))))
char buffer[(sizeof (M)) * (mask + 1)];
static M *m = new (buffer) M[mask + 1];
return m[i];
}
}
// mutex_pool.h
namespace __gnu_internal _GLIBCXX_VISIBILITY(hidden)
{
const unsigned char mask = 0xf;
const unsigned char invalid = mask + 1;
/* Returns different instances of __mutex depending on the passed index
* in order to limit contention.
*/
__gnu_cxx::__mutex& get_mutex(unsigned char i);
}
在这段代码里面,unsigned char i 限制了互斥量池的最大大小为 256。而实际上 mask 为 0xf,说明互斥量池的大小为 16。哈希 + 池化的模式还可见于
libstdc++ 原子变量 wait 和 notify 的实现。
原子模板类对共享指针的偏特化
C++20 std::atomic<std::shared_ptr<T>> 的实现参考 shared_ptr_atomic.h。
template<typename _Tp>
struct _Sp_atomic { // 假设 64 位环境,16 字节
// ...
// An atomic version of __shared_count<> and __weak_count<>.
// Stores a _Sp_counted_base<>* but uses the LSB as a lock.
struct _Atomic_count // 8 字节
{
private:
// 里面实际上是存储了一个指针,并且最低位有特殊含义。
// 因为 atomic 模板类对指针类型有偏特化,而这里需要直接操作位表示,
// 所以存储选择 uintptr_t 类型。
mutable __atomic_base<uintptr_t> _M_val{0}; // 8 字节
static constexpr uintptr_t _S_lock_bit{1}; // 注意是静态,在实例中不占空间
};
private:
typename _Tp::element_type* _M_ptr = nullptr; // 8 字节
_Atomic_count _M_refcount; // 8 字节
};
template<typename _Tp>
struct atomic<shared_ptr<_Tp>> {
// ...
// 将实现转发到 _M_impl 上
private:
_Sp_atomic<shared_ptr<_Tp>> _M_impl;
};
每次对 _Sp_atomic 操作都要调用 _M_refcount.lock() 来上锁。上锁的过程首先是循环等待锁空闲,然后是在循环中调用 compare_exchange_strong,可以看出是自旋锁。对引用计数块上锁之后才能得到其指针,此时 __atomic_base<uintptr_t> 的锁标志已被去除,以指针的形式从 lock() 中返回。
Benchmark 实验
两种实现的性能比较
现在来比较一下原子操作自由函数(互斥量)和原子变量偏特化(自旋锁)两种方案的性能。先创建多个线程,每个线程都会进行若干次先读后写的操作,测量两种方案下的执行时间。
在 quick-bench 下进行测试,在单线程或者循环次数比较少的时候,都是互斥量的性能更优。好像这个网站没有给多核?而且 benchmark 的 CPU 时间应该不能和程序实际运行时间等价。虽然结果没多大意义,但既然做过实验了还是放一下结果。(代码也在链接里面,就不单独列代码了。)
| 线程数 | 循环次数 | 原子操作自由函数 CPU 时间 | 原子变量偏特化 CPU 时间 | 链接 |
|---|---|---|---|---|
| 1 | 1000 | 47,210.516 | 48,898.659 | https://quick-bench.com/q/-GlB8zwmpVm0wxUHqMD1flX8S80 |
| 2 | 1000 | 90,009.0489 | 81,656.665 | https://quick-bench.com/q/jtVQkUQCDV9ZqkJpTHdqJZ1X-fY |
| 4 | 1000 | 230,958.147 | 208,060.813 | https://quick-bench.com/q/Zq3g98LNhSXXFcK_162RNjb-FtM |
| 8 | 1000 | 672,488.446 | 664,635.097 | https://quick-bench.com/q/r07L7P2jwAJxU8CPXb81gV-uoJo |
| 10 | 1 | 620,372.601 | 638,603.319 | https://quick-bench.com/q/AnEMoJYRCGnTZyzmiIRB8n6zpCE |
| 10 | 10 | 752,338.154 | 719,752.91 | https://quick-bench.com/q/8Ee42qG9eRaT6p5Ykj-FuBM-WPQ |
| 10 | 100 | 646,976.937 | 637,434.736 | https://quick-bench.com/q/we2LIuMsreMqNRAAE0BzxDp_3ZI |
| 10 | 1000 | 682,937.478 | 652,523.314 | https://quick-bench.com/q/xNdy-7OXeRTvoBh82i7LmUMk8cw |
| 10 | 10000 | 🚀 844,765.936 | 1,098,030.509 | https://quick-bench.com/q/5Gjos6rN3K2H94PFde5tc_VFmO8 |
为了验证多核环境下的情况,我在笔记本上重新了试了一下。CPU 是 6 + 8 + 2 的第一代 Ultra 9,环境是 WSL2 + Debian 12,GCC 版本为 12.2.0。编译使用 CMake 的 Release 配置,即 -O3。安装 benchmark 库或者将其作为 CMake 的第三方依赖都可以。
| 线程数 | 循环次数 | 原子操作自由函数实际时间 | 原子变量偏特化实际时间 |
|---|---|---|---|
| 1 | 1000 | 90960 ns | 🚀 79325 ns |
| 2 | 1000 | 313173 ns | 🚀 218804 ns |
| 4 | 1000 | 🚀 553431 ns | 930307 ns |
| 8 | 1000 | 🚀 1382092 ns | 3317335 ns |
| 10 | 1 | 305089 ns | 316985 ns |
| 10 | 10 | 326326 ns | 342686 ns |
| 10 | 100 | 314011 ns | 311332 ns |
| 10 | 1000 | 🚀 1974462 ns | 4842926 ns |
| 10 | 10000 | 🚀 22828557 ns | 60812315 ns |
竞争稍微增多一点就是互斥量实现性能更优,基本印证了
要不要使用自旋锁 中的说法:在用户空间实现自旋锁还不如使用 std::mutex。
互斥量池对性能的影响
之前共享指针的原子操作自由函数还有一点令人在意,就是我看到的 libstdc++ 代码里面用了互斥量池。所有共享指针使用同一个互斥量池,而不是每个共享指针实例独占一个互斥量,是否会对性能产生影响?
代码如下:
#include <benchmark/benchmark.h>
#include <memory>
#include <atomic>
#include <thread>
#include <vector>
#include <mutex>
// 可调整的常量
const int N_THREADS = 8; // 线程数
const int N_SHARED_PTRS = 4; // 共享指针数
const int N_OPERATIONS = 1000; // 每个线程的操作次数
// 共享指针数组
std::vector<std::shared_ptr<int>> shared_ptrs(N_SHARED_PTRS);
// 用于保护共享指针的互斥锁数组
std::vector<std::mutex> mutexes(N_SHARED_PTRS);
// 初始化共享指针(只执行一次)
void initialize_shared_ptrs() {
for (int i = 0; i < N_SHARED_PTRS; ++i) {
shared_ptrs[i] = std::make_shared<int>(0);
}
}
// 使用 std::atomic_load 和 std::atomic_store
static void BM_AtomicLoadStore(benchmark::State& state) {
// 初始化共享指针(只执行一次)
initialize_shared_ptrs();
for (auto _ : state) {
std::vector<std::thread> threads;
// 创建线程
for (int i = 0; i < N_THREADS; ++i) {
threads.emplace_back([i]() {
int ptr_index = i % N_SHARED_PTRS; // 分配给线程的共享指针索引
for (int j = 0; j < N_OPERATIONS; ++j) {
auto local_ptr = std::atomic_load(&shared_ptrs[ptr_index]);
std::atomic_store(&shared_ptrs[ptr_index],
std::make_shared<int>(*local_ptr + 1));
}
});
}
// 等待所有线程完成
for (auto& t : threads) {
t.join();
}
}
}
BENCHMARK(BM_AtomicLoadStore);
// 使用 std::mutex 保护共享指针
static void BM_MutexProtected(benchmark::State& state) {
// 初始化共享指针(只执行一次)
initialize_shared_ptrs();
for (auto _ : state) {
std::vector<std::thread> threads;
// 创建线程
for (int i = 0; i < N_THREADS; ++i) {
threads.emplace_back([i]() {
int ptr_index = i % N_SHARED_PTRS; // 分配给线程的共享指针索引
for (int j = 0; j < N_OPERATIONS; ++j) {
// Not exactly equivalent to std::atomic_load + std::atomic_store
// ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
// std::lock_guard<std::mutex> lock(mutexes[ptr_index]);
// auto local_ptr = shared_ptrs[ptr_index];
// shared_ptrs[ptr_index] = std::make_shared<int>(*local_ptr + 1);
std::shared_ptr<int> local_ptr;
{
std::lock_guard<std::mutex> lock(mutexes[ptr_index]);
local_ptr = shared_ptrs[ptr_index];
}
{
std::lock_guard<std::mutex> lock(mutexes[ptr_index]);
shared_ptrs[ptr_index] = std::make_shared<int>(*local_ptr + 1);
}
}
});
}
// 等待所有线程完成
for (auto& t : threads) {
t.join();
}
}
}
BENCHMARK(BM_MutexProtected);
BENCHMARK_MAIN();
结果:
| 线程数 | 共享指针总数 | 循环次数 | 原子操作自由函数耗时 | std::mutex 耗时 |
|---|---|---|---|---|
| 1 | 4 | 1000 | 89058 ns | 80306 ns |
| 2 | 4 | 1000 | 🚀 105798 ns | 228047 ns |
| 4 | 4 | 1000 | 🚀 268838 ns | 387156 ns |
| 8 | 4 | 1000 | 🚀 588483 ns | 656299 ns |
| 16 | 4 | 1000 | 🚀 1189470 ns | 1379560 ns |
| 32 | 4 | 1000 | 🚀 2693715 ns | 3517673 ns |
| 64 | 4 | 1000 | 🚀 6599134 ns | 8734254 ns |
| 128 | 4 | 1000 | 🚀 14365890 ns | 20750675 ns |
在共享指针总数为 4 时,自行维护互斥量的性能更差!这可能是因为我们自行对互斥量上锁,会有共享指针赋值操作符中原子操作的开销,而共享指针原子操作的读写将上锁的过程合并到了一起,效率更高。
考虑到共享指针为 4 时互斥量池哈希冲突可能不够大,为了体现使用互斥量池的劣势,接下来增大共享指针总数,测试结果反过来了🤯:
| 线程数 | 共享指针总数 | 循环次数 | 原子操作自由函数耗时 | std::mutex 耗时 |
|---|---|---|---|---|
| 128 | 8 | 1000 | 11025946 ns | 🚀 8755322 ns |
| 128 | 16 | 1000 | 6816762 ns | 🚀 5489590 ns |
| 128 | 32 | 1000 | 5502325 ns | 5297484 ns |
| 128 | 64 | 1000 | 5625533 ns | 5377507 ns |
| 1024 | 32 | 1000 | 54262267 ns | 🚀 37587115 ns |
| 1024 | 64 | 1000 | 42344566 ns | 🚀 36543750 ns |
| 1024 | 128 | 1000 | 42877169 ns | 🚀 36769052 ns |
| 1024 | 256 | 1000 | 39072114 ns | 38813602 ns |
| 1024 | 512 | 1000 | 37306563 ns | 36461196 ns |
| 1024 | 1024 | 1000 | 39054127 ns | 38676024 ns |
| 8092 | 512 | 1000 | 270409075 ns | 🚀 238338752 ns |
| 8092 | 2048 | 1000 | 281548516 ns | 🚀 242187529 ns |
| 8092 | 8092 | 1000 | 275440750 ns | 🚀 236298876 ns |
当线程总数超过线程池大小时,原子操作自由函数的耗时确实比外部的 std::mutex 多。
Note
多试几次可能会出现测出来的结果相差很大的情况(有时候耗时差不多,有时候耗时比接近 2),有可能是哈希结果随着共享指针地址变化,每次启动程序时共享指针分配互斥量的均匀程度不同。
画折线图看趋势
固定线程数为 1024,操作次数为 1000,#n 表示共享指针总数是 n。将实验数据整理成这样的格式:
#1
-------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------
BM_AtomicLoadStore 248032779 ns 28470177 ns 13
BM_MutexProtected 237027562 ns 28843112 ns 25
BM_AtomicSharedPtr 1.8736e+10 ns 43095100 ns 1
#2
-------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------
BM_AtomicLoadStore 168213275 ns 46402056 ns 16
BM_MutexProtected 320855445 ns 39238330 ns 10
BM_AtomicSharedPtr 8455017155 ns 32803500 ns 1
画图代码:
import matplotlib.pyplot as plt
# 读取文件并提取数据
with open('benchmark.log', 'r') as file:
lines = file.readlines()
# 初始化存储数据的字典
data = {
'BM_AtomicLoadStore': {'n': [], 'time': []},
'BM_MutexProtected': {'n': [], 'time': []},
'BM_AtomicSharedPtr': {'n': [], 'time': []}
}
# 解析数据
current_n = None
for line in lines:
if line.startswith('#'):
current_n = int(line.strip().replace('#', ''))
elif 'BM_' in line:
parts = line.split()
benchmark_name = parts[0]
time_ns = float(parts[1].replace('ns', ''))
data[benchmark_name]['n'].append(current_n)
data[benchmark_name]['time'].append(time_ns)
# 绘制图形
plt.figure(figsize=(10, 6))
# 极端大的数据影响画图,头两个数据就不要了
data['BM_AtomicSharedPtr']['time'][0] = float('nan')
data['BM_AtomicSharedPtr']['time'][1] = float('nan')
for benchmark_name, values in data.items():
plt.plot(values['n'], values['time'], marker='o', markersize=5, label=benchmark_name)
plt.xlabel('n')
plt.ylabel('Time (ns)')
plt.title('Benchmark Time vs n')
plt.legend()
plt.grid(True)
plt.show()
结果:
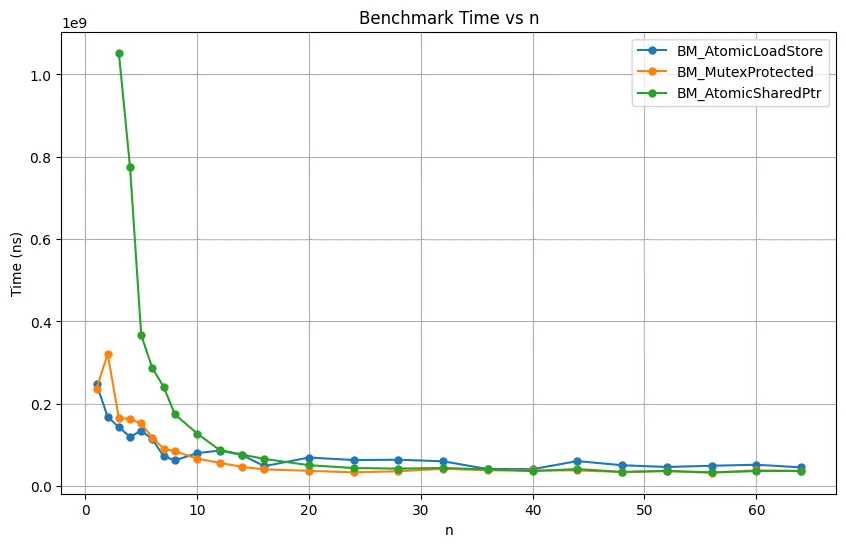
自变量 n 即共享指针总数(即锁的数量),越大竞争越少。对上图做出以下观察:
- BM_AtomicSharedPtr 基本上总是不如 BM_MutexProtected 性能好。前者是自旋锁,后者使用了 pthread 的 mutex。
- BM_AtomicLoadStore 在 n 比较小的时候性能比 BM_MutexProtected 好。可能是因为它能在上锁后直接获取共享指针的控制块,在控制块上就只需要做平凡操作而不是原子操作。
- BM_AtomicLoadStore 在 n 增大时性能不如 BM_MutexProtected。这时其性能已经受到了互斥量池容量大小的限制。
- 在 n 非常大时,BM_AtomicLoadStore 尽管仍不如 BM_MutexProtected,但是也没有显著地更差。可能是因为个人电脑的核心数并不多,测试中互斥量池大小受限最多只允许 16 个线程同时操作,但我的笔记本加上超线程(不算超小核)也才 20 个线程。
Perf 实验
再试试 perf(perf 在 WSL2 上的安装参考 WSL2 中安装 perf)。每次注释掉其他代码,只对单个测试跑 perf:
$ perf record ./build/main
...
$ perf report --demangle
... # 这里会在终端中显示不同函数运行占用的 CPU 时间
实际测试发现在有 perf 的情况下,维护外部互斥量的 benchmark 耗时会增加,说明 perf 也会影响 benchmark,那这个时候我们就只看 perf 结果不看 Google Benchmark 的结果了。实验选定的线程数为 1024,共享指针总数为 32,每个线程要执行的操作数为 1000。新增对共享指针用例的测试:
// 新增:atomic shared_ptr 数组
std::vector<std::atomic<std::shared_ptr<int>>> atomic_shared_ptrs(N_SHARED_PTRS);
static void BM_AtomicSharedPtr(benchmark::State& state) {
// 初始化共享指针(只执行一次)
initialize_shared_ptrs();
for (auto _ : state) {
std::vector<std::thread> threads;
// 创建线程
for (int i = 0; i < N_THREADS; ++i) {
threads.emplace_back([i]() {
int ptr_index = i % N_SHARED_PTRS; // 分配给线程的共享指针索引
for (int j = 0; j < N_OPERATIONS; ++j) {
auto local_ptr = atomic_shared_ptrs[ptr_index].load(); // load
atomic_shared_ptrs[ptr_index].store(
std::make_shared<int>(*local_ptr + 1)); // store
}
});
}
// 等待所有线程完成
for (auto& t : threads) {
t.join();
}
}
}
BENCHMARK(BM_AtomicSharedPtr);
结果:
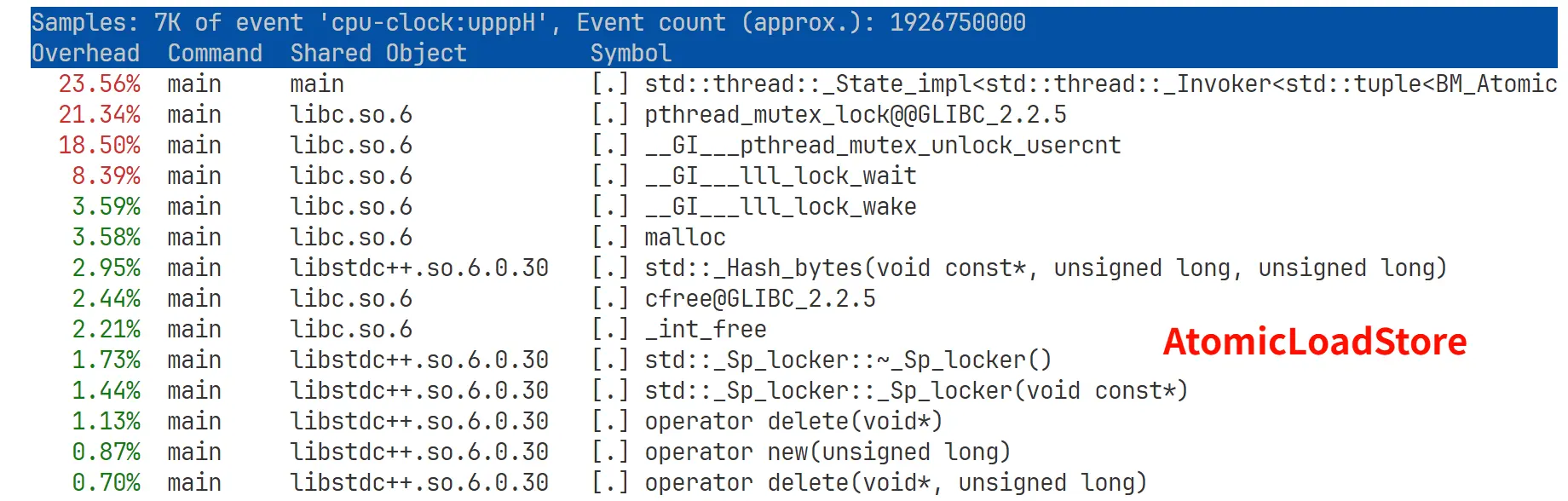
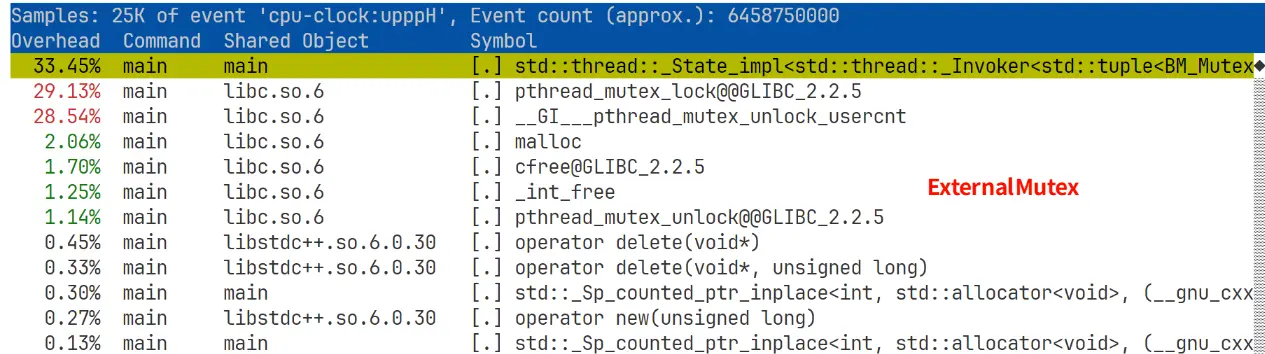
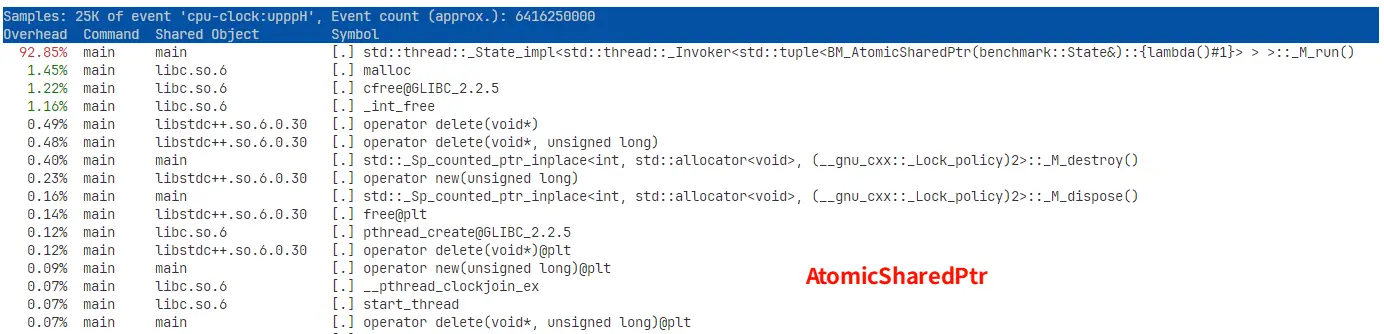
这个比 benchmark 的结果稳定一些,多试几次基本一样。耗时最多的 lambda 函数就是启动 thread 时创建的工作函数。
- 看起来 ExternalMutex 在工作函数内以及 mutex 操作耗费的 CPU 时间占比更多,可能表明其休眠比 AtomicLoadStore 少,从而表明其互斥量竞争不如 AtomicLoadStore 严重。
- AtomicSharedPtr 实验中超过 92% 的 CPU 时间都花在了工作函数里面,体现了其自旋性质。因为
-O3将很多操作都内联了,所有原子操作耗时都加在了一个函数里面。 - 这组运行参数是自旋锁的甜点配置,虽然这里没有列出来,但实际性能是 ExternalMutex > AtomicSharedPtr » AtomicLoadStore,说明 1024 个线程均匀分配到 32 个锁上对于自旋锁来说竞争并不算激烈。不过考虑到自旋锁依然不如
std::mutex的性能好,所以建议还是直接用std::mutex。
总结
C++20 之前可以用 std::atomic_* 这些自由函数对共享指针做原子操作,在 libstdc++ 中依靠的是一个互斥量池,有些共享指针可能会映射到同一个互斥量。C++20 之后这些自由函数被标记为过时,同时 std::atomic<> 对共享指针有了偏特化,在 libstdc++ 中实质是自旋锁。系统负载增大时,互斥量版的实现比自旋锁版的实现性能好。
std::atomic_* 对共享指针操作时使用互斥量池,其大小只有 16,效果竟惊人地好。在低负载的情况下,其性能比对每个共享指针手动创建一个互斥量好;在高负载的情况下,尽管互斥量池的冲突增加,其性能也只是略低于手动创建互斥量。只有在中等负载情况下,即 $线程数 / 共享指针总数$ 适中时,手动维护互斥量的收益更大,有时候能达到 1.7 倍的性能差距。原因可见前文的猜测(
画折线图看趋势)。