4. Synchronizing concurrent operations
这一章主要讲线程之间的同步和信息传递,包括条件变量(condition variable)、futures、latches/barries。
条件变量
头文件是 <condition_variable>。包含 std::condition_variable 和 std::condition_variable_any。前者只能在 std::mutex 上使用,后者可以在所有满足 BasicLockable(lock() + unlock(),不需要 try_lock())的类型上使用。如果只需要使用 std::mutex,那么就用前者,开销可能会比后者小一点。
Tip
接口只有一处区别:std::condition_variable 可以获取 native handle,而 std::condition_variable_any 不能。
条件变量可以用来协调生产者和消费者之间的关系。
典型操作流程:
- 先用
std::unique_lock获得锁。 - 然后用条件变量来等待锁。这个过程需要一个 pred(用来检查条件是否满足),如果条件已经满足则会直接返回;否则释放锁并陷入休眠,直到自发唤醒(spurious wake)或者被通知(notify)。
使用方法可以参考 https://en.cppreference.com/w/cpp/thread/condition_variable 。
之所以不用 std::lock_guard 是因为条件变量的等待对象必须是可解锁的。而 std::unique_lock 又比直接对 std::mutex 操作安全。
案例:线程安全的队列
和第 3 章中线程安全栈一样,书上还是提供了两种重载,一种用传出参数来返回结果,一种返回共享指针。同时,由于队列常常用来协调消费者和生产者之间的关系,因此又有阻塞等待和轮询两个版本。
bool try_pop(T &value);
std::shared_ptr<T> try_pop(); // 如果失败就返回空指针
void wait_and_pop(T &value);
std::shared_ptr<T> wait_and_pop();
如果生产者完成了生产,那么可以用 notify_one 来通知一个消费者。如果是一个线程完成初始化操作,其他所有线程都能来读取结果,那么可以用 notify_all 来通知。
未来(Future)
如果条件变量只需要等待一次,那么用 std::future 可能会更加合适,它表示一个异步任务的结果。比较:std::future 是一次性的、而且可以携带数据(如果不携带数据,模板参数就是 void)。std::condition_variable 是可以重复使用的,本身不能携带数据。
C++ 提供了两种 futures:std::future 和 std::shared_future。
std::async
用 std::async 创建任务是获取 future 的一种方式。在 <future> 头文件中,C++ 还提供了 std::async 函数模板。std::async 的启动参数可以是 std::launch::async 或者 std::launch::deferred,或者两者都可(默认)。如果启动被延迟,则计算只会在等待或获取结果时才开始计算。

std::packaged_task
可以和线程池结合使用。
std::packaged_task 的模板参数的含义和 std::function 非常相似。不同之处是 std::function 是同步调用,(只有)调用者可以获取任务的结果,而 std::package_task<> 通过暴露出一个 std::future,将计算和获取结果的过程分开,从而计算可以异步进行。
std::packaged_task 只能被成功调用一次,后续的调用将抛出 std::future_error 异常。而 std::function 则可以多次调用。
感觉 std::async 也是可以用 std::packaged_task 来实现的,前者强调提交任务的功能,后者只是表示任务这个实体。
#include <cmath>
#include <functional>
#include <future>
#include <iostream>
#include <thread>
// unique function to avoid disambiguating the std::pow overload set
int f(int x, int y) { return std::pow(x, y); }
void task_thread() {
std::packaged_task<int(int, int)> task(f);
std::future<int> result = task.get_future();
std::thread task_td(std::move(task), 2, 10);
task_td.join(); // 这里 detach 也没有关系,因为下面 result.get() 会同步
std::cout << "task_thread:\t" << result.get() << '\n';
}
int main() { task_thread(); }
std::promise
从 std::async 到 std::packaged_task,再到 std::promise,它们实现的功能越来越基础。std::promise 解决了 std::packaged_task 的局限性:有时候获取结果的过程并不能用一个函数来简单表达。
就像 std::packaged_task 一样,我们可以用 get_future() 来从 std::promise 上获取 future,生产者用 set_value 设置结果。std::promise 还有设置异常的功能:
// 1
extern std::promise<double> some_promise;
try
{
some_promise.set_value(calculate_value());
}
catch(...)
{
some_promise.set_exception(std::current_exception());
}
// 2
some_promise.set_exception(std::make_exception_ptr(std::logic_error("foo ")));
如果 std::promise 被析构,但是没有被调用过 set_value() 或者 set_exception(),那么就会存储一个带有 std::future_errc::broken_promise 错误码的 std::future_error 异常。
std::promise 还有 set_value_at_thread_exit() 和 set_exception_at_thread_exit 方法,可以防止遗漏赋值。
std::shared_future
std::future 没有考虑多个消费者之间的数据竞争,所以只能被一个消费者使用,而且是 move-only 的类型;而 std::shared_future 可以被多个消费者使用,是 copyable 的类型。不过,不同线程应该获取 std::shared_future 的副本,而不是使用同一个引用,才能避免数据竞争。Cppreference 上给了一个前提:
Access to the same shared state from multiple threads is safe if each thread does it through its own copy of a
shared_futureobject.
https://stackoverflow.com/a/73835675/ 有更详细的解释:std::future 上的等待也是安全的,但是 get() 不是。std::future 的 get() 对非引用类型返回的是值类型,结果被取走之后就没有了。尝试对一个结果取多次会报错 std::future_error: No associated state,就算取走结果之后想要再调用 set_value() 也会报错 std::future_error: Promise already satisfied。
而 std::shared_future 的 get() 对非引用类型返回常量引用,只要有一个消费者还持有对结果的引用,那么结果就不会被销毁(就像 std::shared_ptr 那样)。因此在 std::shared_future 上可以多次调用 share()。Compiler Explorer 上的例子。
Note
对于引用类型,std::future 和 std::shared_future 都是返回引用类型本身。
我们需要从 std::future 中创建 std::shared_future,要么传入右值(亡值或者纯右值)来构建:
// 1
std::promise<int> p;
std::future<int> f(p.get_future());
assert(f.valid());
std::shared_future<int> sf(std::move(f));
assert(!f.valid());
assert(sf.valid())
// 2
std::promise<std::string> p;
std::shared_future<std::string> sf(p.get_future());
要么调用 std::future 的 .shared() 方法:
auto sf = p.get_future().share();
等待一段时间
之前介绍的等待函数都只能永久等待,不能指定等待的时间。这个小节还介绍了一些 std::chrono 中的 API。
std::chrono API
时钟:
std::chrono::steady_clockstd::chrono::system_clock不是稳定的,因为时间可以设定。其 time_point 可以和std::time_t通过to_time_t和from_time_t相互转换。std::chrono::high_resolution_clock
时间:
std::chrono::duration<> 的模板参数是表示类型(比如 double)和 ratio(单位是秒)。
在 std::chrono 中有很多时间单位的定义:nanoseconds, microseconds, milliseconds, seconds, minutes, hours 等。在 std 中有很多 SI 比例的定义:std::atto(1e-18)、std::exa(1e18)等,见 https://en.cppreference.com/w/cpp/numeric/ratio/ratio 。尤其是要注意 std::milli、std::micro、std::nano 这些是 SI 比例,而不是时间单位。
用字面量后缀操作符更方便地表示时间:
using namespace std::chrono_literals;
auto one_day=24h;
auto half_an_hour=30min;
auto max_time_between_messages=30ms;
从一个时间单位转换到另外一个时间单位用 std::chrono::duration_cast。此外,duration 还支持算术运算!
时刻(时间点):
std::chrono::time_point<>。时间点的值是相关时钟的纪元(epoch)。
Although you can’t find out when the epoch is, you can get the
time_since_epoch()for a given time_point. This member function returns a duration value specifying the length of time since the clock epoch to that particular time point.
wait_for 和 wait_until
wait_for 配合时间,wait_util 配合时刻。很多时候 wait_until 比 wait_for 更合适,比如在循环中等待条件变量但是又不传 predicate 的时候,由于虚假唤醒的存在,wait_* 可能会被调用多次,那么 wait_until 能更加准确地表示时间,而不是(可能)永远无法离开循环。(所以用条件变量还是传 predicate 比较好。)
案例:parallel_quick_sort
书中使用 std::list 的 splice() 操作、std::partition 操作和 std::async 操作来实现了一个并行的快速排序算法。这个快速排序算法遵循函数式编程的思想,只对输入做更改,并将结果以返回值的形式体现。每次找到 pivot 的时候都用 std::async 创建一个新的任务。现在只有子区间是并行的,分区过程本身不是并行的。
在默认策略下,std::async 不一定每次都要创建新的线程,是否创建新的线程由库的实现决定。
案例:用自动状态机思想实现 ATM 类
书里前面讲了 FP,这里实现 ATM 则是为了体现 CSP 的思想。这份代码很有意思,通过一个指向成员函数的指针来转移状态,比设置枚举量,然后用 switch 来跳转要显得更加优雅。

这种编程范式又被叫做演员模型(Actor Model),每个线程充当一个角色,执行不同的任务。
Concurrency TS 中的 `std::experimental::future
增加了延续(continuation)的概念,可以用 then 函数来组织 futures(Java、Javascript 都有类似的函数)。但是这个提案被废弃,并被(被认为更好的) executors 来代替,后者被包含在 C++26 中。
std::experimental::shared_future 也可以用 then,而且可用多次。
The difference here is that
std::experimental::shared_futureobjects can have more than one continuation, and the continuation parameter is astd::experimental:: shared_futurerather than astd::experimental::future.
等待一组 futures
如果有一组 futures 需要等待,而且等待的过程是由当前接口的使用方来进行的,那么可以创建一个新的 future,并且在这个 future 里面等待之前的所有 futures。
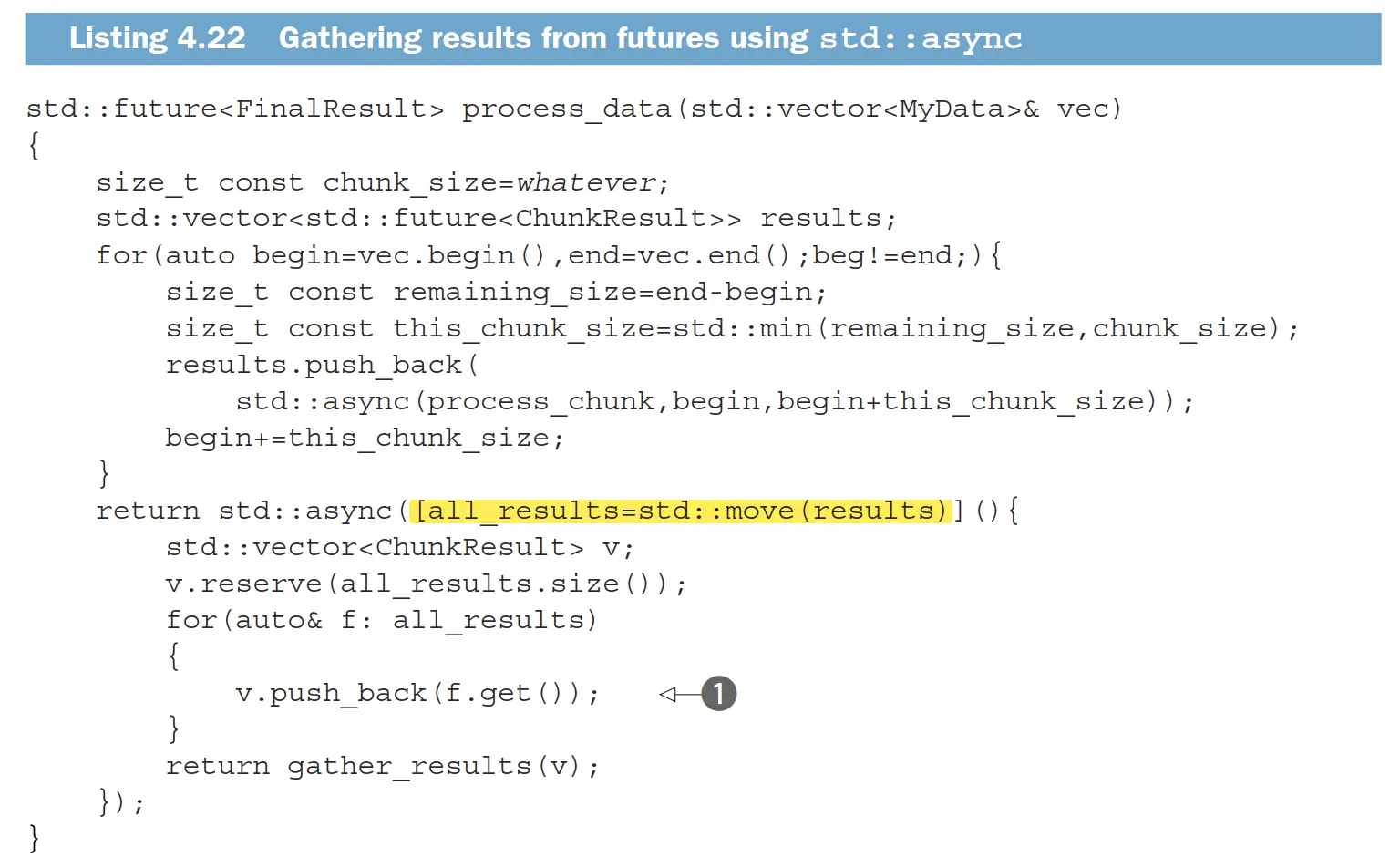
我认为这里可以添加一个 std::launch::deferred 标记,这样就不必为“等待”这个过程创建一个新的线程了。
在 Concurrency TS 中有 std::experimental::when_all(返回一组 futures) 和 std::experimental::when_any(返回一个 match_any_result,它包含原来的 futures 和首先可用的 future 的下标),它们分别创建在 futures 都可用时可用的新 future,和至少有一个可用就可用的新 future。前者(when_all)可以由上面截图的代码来模拟。后者在书上没有给出模拟的代码。
std::latch 和 std::barrier
写书时这两个类还在 Concurrency TS 中,现在这两个类已经加入 C++20 中。
std::latch
std::latch 模型比较简单,只能使用一次,一旦计数降低(count_down())到 0,就永远保持在 ready 状态(在 Concurrency TS 中可以用 is_ready() 查询,而在 C++20 中有 try_wait() 方法来查询)。
std::barrier
C++20 的 std::barrier 是结合了 Concurrency TS 中 barrier 和 flex_barrier 特性的类。它是一个模板类,但是 std::experimental::barrier 和 std::experimental::flex_barrier 不是。
Note
std::experimental::flex_barrier 接受 completion 函数,但是居然不是类模板,应该是有类型擦除。
template< class CompletionFunction = /* ... */ >
class barrier;
接下来的内容会直接介绍 std::barrier,并指出它和 std::experimental::barrier 的区别。
std::barrier 和 std::string 不一样,std::string 是 std::basic_string 的特化,是一个具体的类,而 std::barrier 是一个类模板,虽然在定义时可以利用 CTAD,显得和普通类没有区别,但是在声明时必须体现它是模板类。
#include <barrier>
struct Foo {
- std::barrier b; // ❌
+ std::barrier<> b; // ✔
};
它还有个静态常量函数是 max,表示当前实现中允许的最大初始值。在 我的一个测试 中返回 64 位有符号数的最大值(不代表每个平台都是这样)。
很常见的一个 barrier 的使用场景是用 CUDA 中的 __syncthreads() 完成块内的同步。
构造函数
constexpr explicit barrier( std::ptrdiff_t expected,
CompletionFunction f = CompletionFunction());
barrier( const barrier& ) = delete;
第二个构造函数的声明标志着拷贝构造函数、移动构造函数 / 赋值操作符的删除。可以参考 C++ - Rule of 3, 5, 0。
成员函数
std::barrier 可以反复使用,一组线程必须要一起来到等待点才能通过,都通过等待点之后计数器就会重置。每一轮叫做 barrier phase。其设计思想是:只有在同步组中的线程才能使用 arrive() 来减少计数,而且在每个 phase 只能 arrive 一次。它有以下几个方法:
arrive : 计数减 1,返回 arrival_token
wait : 在同步点(phase synchronization point)等待计数归零,需要 arrival_token 作为参数
arrive_and_wait: 计数减 1,并且在同步点等待计数归零
arrive_and_drop: 计数减 1,并且退出同步组
std::barrier 有一个删除了的 operator=,这也标志着其无法拷贝赋值。(注意:禁用拷贝构造并不会禁用拷贝赋值,两者需要分别禁用。)
✨ arrive() 和 wait()
也就是说,如果不想阻塞其他线程继续前进,可以使用 arrive 而不是 arrive_and_wait,但是接下来要用 wait 同步,同时要传入之前 arrive 返回的 arrival_token。参考 https://stackoverflow.com/questions/72213987/how-to-use-c-stdbarrier-arrival-token 。arrive() 和 wait() 是 std::barrier 相比 std::experimental::barrier 多出的两个函数。
✨ completion 函数
和只能指定线程数量的 std::experiment::barrier 相比,std::barrier 还可以指定 completion 函数,这个函数在所有线程达到同步点时运行,而且只会被一个线程运行。从 https://godbolt.org/z/1hMKKqve5 的结果来看,应该是被最后一个到达同步点的线程运行。如果没有线程调用 wait(),那么 completion 函数是否被调用是实现定义的:
A barrier phase consists of the following steps:
- The expected count is decremented by each call to
arriveorarrive_and_drop.- When the expected count reaches zero, the phase completion step is run, meaning that the
_completion_is invoked, and all threads blocked on the phase synchronization point are unblocked. The end of the completion step strongly happens-before all calls that were unblocked by the completion step return.
Exactly once after the expected count reaches zero, a thread executes the completion step during its call toarrive,arrive_and_drop, orwait, except that it is implementation-defined whether the step executes if no thread callswait.- When the completion step finishes, the expected count is reset to the value specified at construction less the number of calls to
arrive_and_dropsince, and the next barrier phase begins.
上述引用也表明最后一个到达的线程会在调用 arrive 等方法的时候来执行 completion 函数。
Completion 函数可以简化很多代码逻辑,特别是每一轮需要清理工作时。如果没有 completion 函数,而是由 0 号线程完成清理工作,为了防止其他线程在清理工作完成之前进入下一轮工作,需要增加一个同步点——在第二个同步点只有 0 号线程在完成清理工作,其他线程阻塞等待。一方面是逻辑代码会显得复杂,另一方面是其他线程刚被唤醒又要再次进入睡眠状态等待清理工作完成。
std::experimental::flex_barrier
Concurrency TS 中还有一个 flex_barrier,但是没有进入 C++20。这个类可以随时修改同步组中的线程数量,还可以指定所有线程到达同步点时要运行的 completion 函数(std::experiment::barrier 没有这个功能,但是 std::barrier 有)。flex_barrier 可以通过 completion 函数的返回值来修改下一轮同步组中的线程数量,-1 表示不改变,非负表示下一轮同步组中的线程数量,这个特性是 std::barrier 不具备的。