2025-09-18 使用美国节点访问 kimi.com
偶然发现使用美国节点并且界面为英文访问 kimi.com 时,能触发不同的搜索源,在某些场景下可能带来更好的搜索效果。
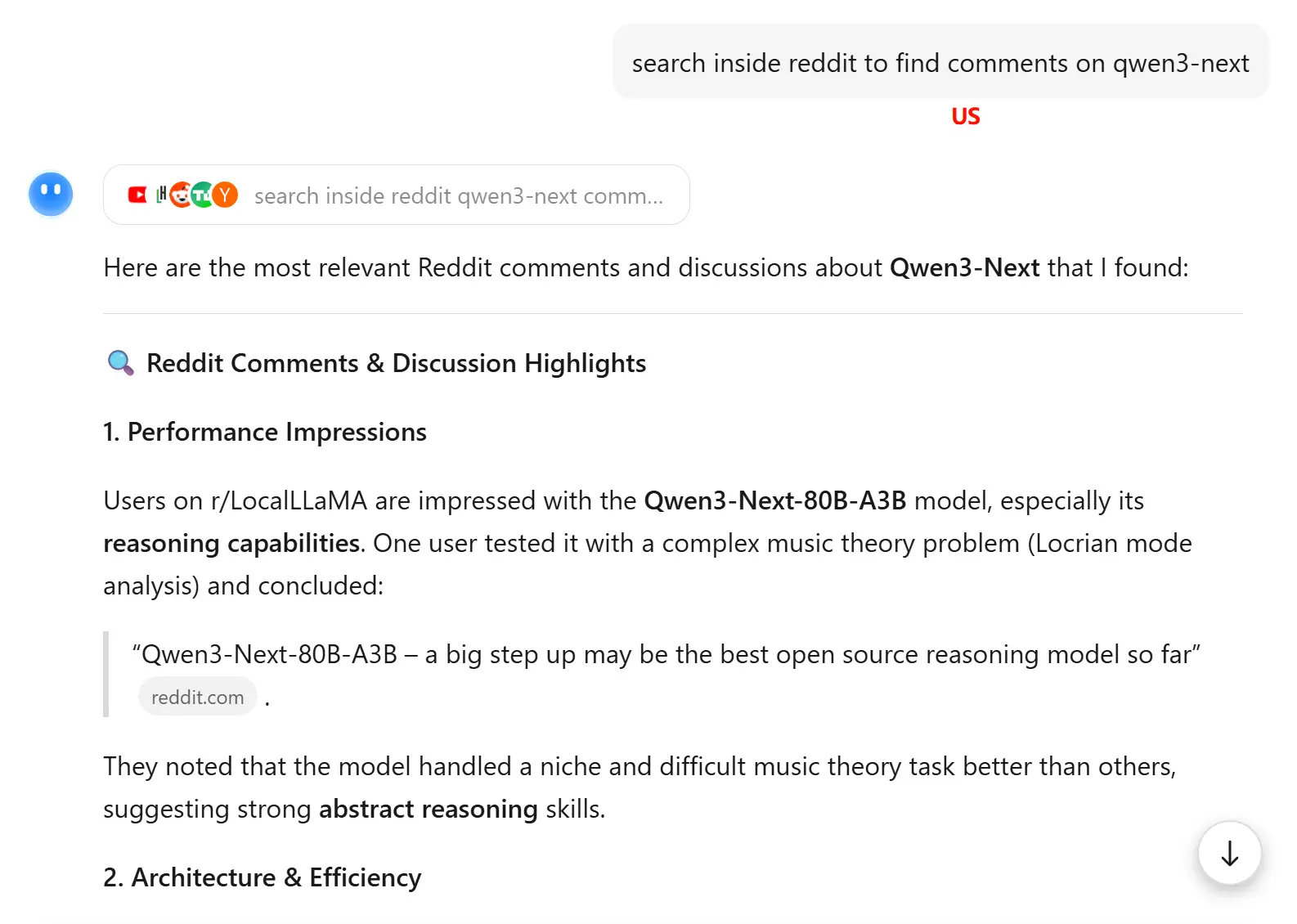
但有时候效果会变差:

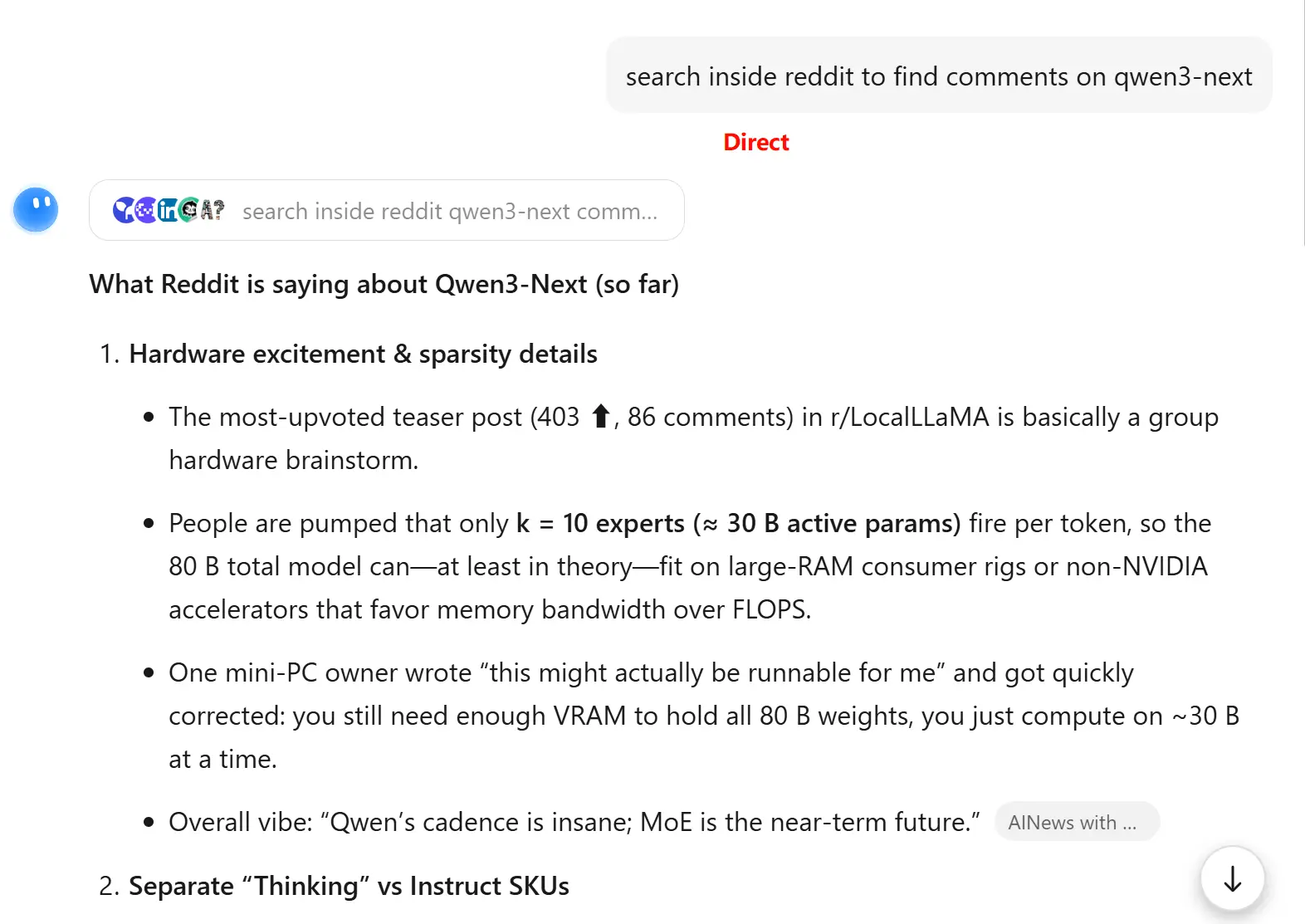
偶然发现使用美国节点并且界面为英文访问 kimi.com 时,能触发不同的搜索源,在某些场景下可能带来更好的搜索效果。
但有时候效果会变差:
CUDA_DEVICE_MAX_CONNECTIONS 这个环境变量在 Megatron-LM 源码中经常见到,主要是用来控制硬件调度 kernel 的顺序,以尽可能提高通信计算重叠场景的重叠率。
英伟达文档 cuda-environment-variables 说明了 CUDA_DEVICE_MAX_CONNECTIONS 默认为 8,可以设置为 1 到 32 的整数值,表示计算和拷贝队列的数量。(同样还有 CUDA_DEVICE_MAX_COPY_CONNECTIONS 表示对拷贝队列的设置(优先级高于 CUDA_DEVICE_MAX_CONNECTION)。)论坛回复 指出这个环境变量表示有多少个硬件队列和 CUDA 流发生映射关系。(如果这个值不够大则流之间存在虚假依赖。这样一来,设置为 1 就能完全保证 kernel 执行顺序和发起顺序一致。设置为 32 则尽可能设法让不同的流并发执行 kernels。)
Megatron-LM 2025.8.1 的提交支持了 1F1B + EP A2A overlap,也对 CUDA_DEVICE_MAX_CONNECTIONS 环境变量有描述。
代码:

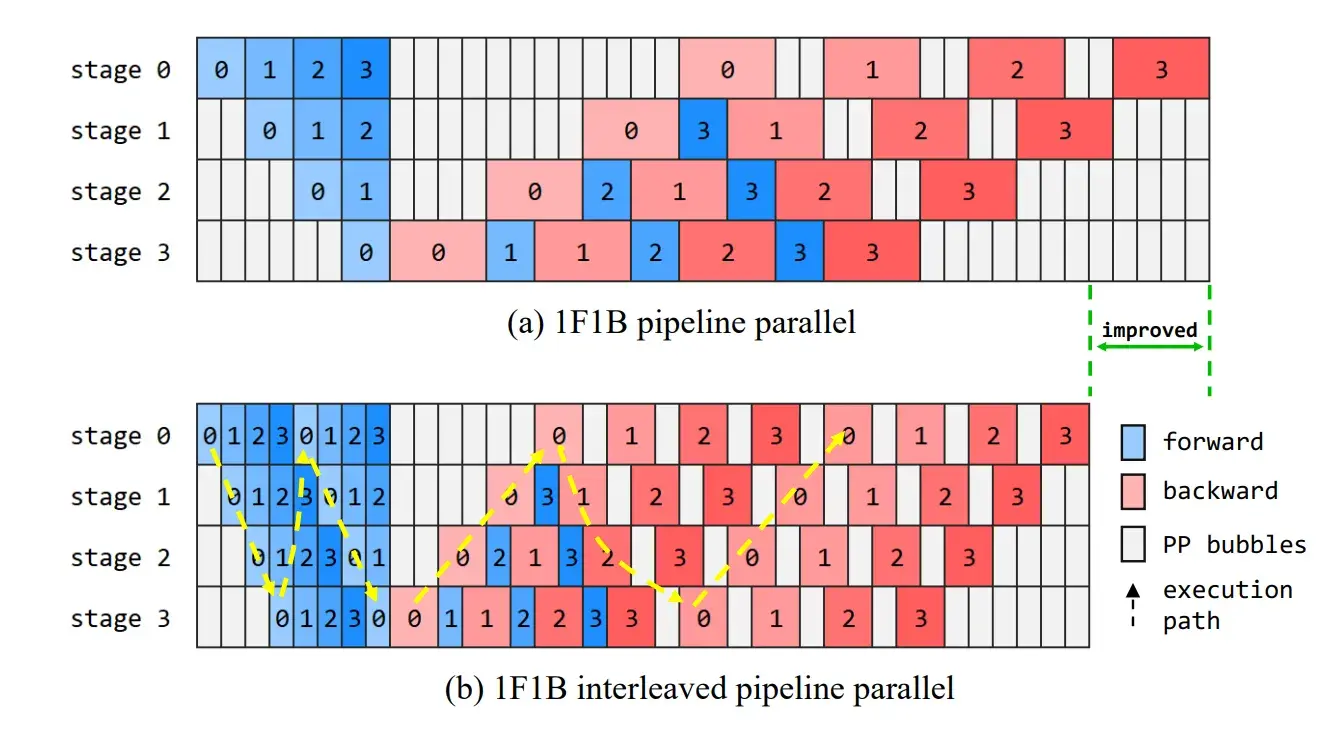
见到过两种画法:一是 device 1 调度到 PP*VPP 个微批次之后继续调度,二是 device 1 调度到 PP*VPP 微批次之后就停下了。
这个是 Megatron 的论文 Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM 第 3 页 https://arxiv.org/pdf/2104.04473 ,同时显示了交错和非交错状态下 1F1B 的调度方式。
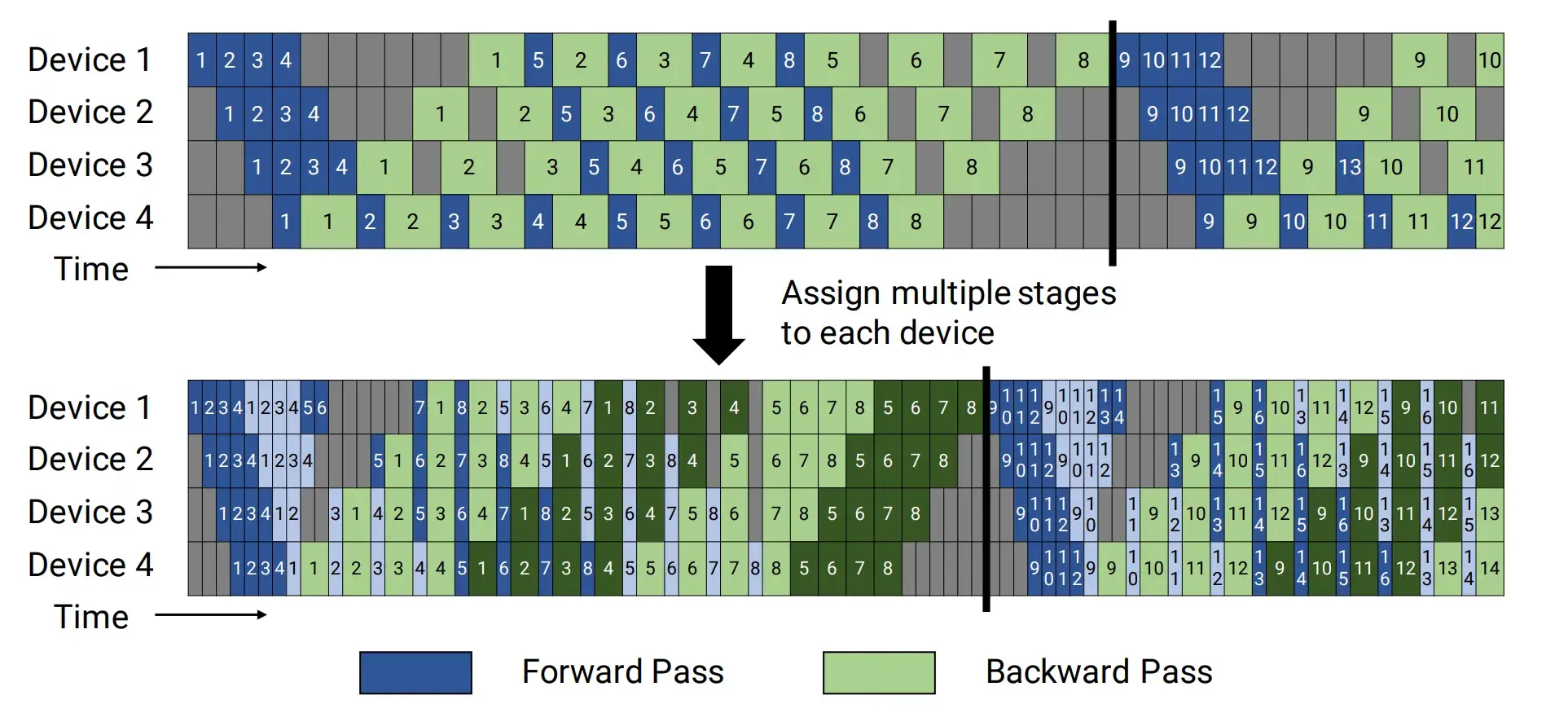
这个是盘古的论文 Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs 第 7 页 https://arxiv.org/pdf/2504.07866 。无论是交错还是非交错 1F1B 均和 Megatron 论文画法有差异。

CUDA_DEVICE_MAX_CONNECTIONS下图标注了 MLA 的一种计算方式,橙色虚线部分可以被包裹到重计算中,入口为 q1,kv1 和 k_rope1(不保存 kv1 和 k_rope1 而是保存 kv1_and_k_rope 也可以,它们的大小一样,没区别)。flash_attn 比较特殊,除了保存输入之外还会保存输出。
如果要做 TP,需要保持 down_proj 为完整矩阵,在 up_proj 矩阵做列切分,在 o_proj 做行切分。如果要做 CP,需要在 attention 的位置插入 CP 策略。

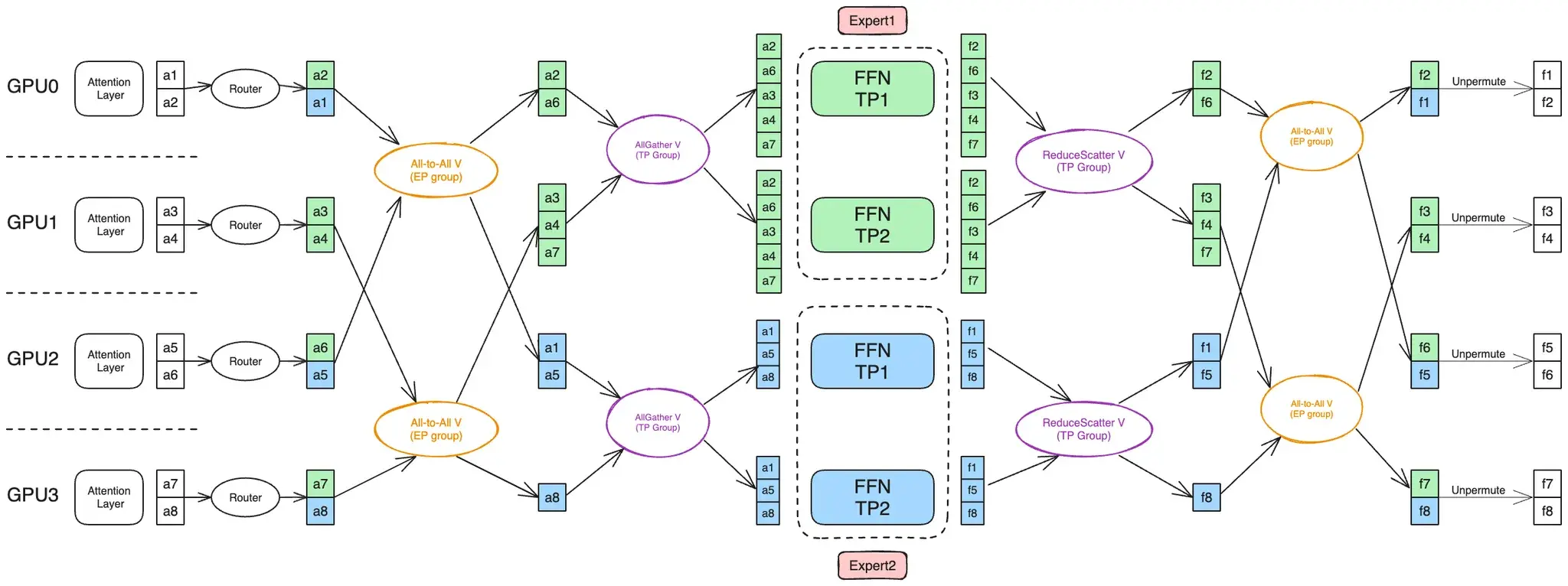
DeepEP 假设了本地 node 用 NVLINK 连接的卡数为 8,因此 EP 必须在最内层。Megatron 在 MoEFlexTokenDispatcher 接入 DeepEP,也必须满足这个假设。
在 MoE Parallel Folding 下,MoE 层的 CP 消失,排在 EP 内层的只有 TP,Megatron 是如何处理 ETP > 1 的情况的?它将 routing map 展开了 tp_size 份,直接用 DeepEP 分发(这个时候使用 TP-EP 组而不是 EP 组,大小为 ep_size * tp_size),这样就满足了 DeepEP 的假设,实质上利用 DeepEP 把 TP 的通信也做了。
我认为 MoE Parallel Folding 的优势是:1. 兼容 DeepEP;2. 把 Attention 和 MoE 的 TP 数解耦;3. 为 EP 让出了 CP 的范围,使得 EP 通信组排列更局部,通信效率更高。
一般来说 MoE 层的 ETP 通信是先做 AlltoAll 再做 AllGather。因为 AllGather 会在 TP 组内形成冗余(大家都拿到一模一样的输入),所以应该只在真正需要用到之前才做 AllGather,将 AllGather 放在 AlltoAll 后可以减少 AlltoAll 的通信量(图片来自 MoE Parallel Folding 论文,上文已给出链接):
内容由 AI 生成
NCCL 2.12 的核心改进包括:
这些进步使 all2all 性能提升了两倍以上,并为复杂的 GPU 拓扑中的模型并行性提供了更大的灵活性。
虽然看上去是三项功能,但是从描述来看都是 PXN 使得它们得以实现,所以实际上主要改进还是 PXN 的引入。
GPU 不是在其本地内存中为本地 NIC 发送数据准备缓冲区,而是在中间 GPU 上准备缓冲区,通过 NVLink 写入。然后它通知管理该 NIC 的 CPU 代理数据已准备好,而不是通知其自己的 CPU 代理。GPU-CPU 同步可能会稍微慢一些,因为它可能需要跨越 CPU 插槽,但数据本身仅使用 NVLink 和 PCI 交换机,确保最大带宽。
原来的 alltoall 传输前是要在发送方准备数据缓冲区的,local rank 0 如果想要发给 peer rank 3 就需要先在自己这里准备数据,然后经过多层路由传输给 peer rank 3。现在是在 local rank 3 上准备数据缓冲区(应该是 RDMA 用),local rank 0 通过 nvlink 将数据传输给 local rank 3,然后 local rank 3 发给 peer rank 3。因为后两者属于同一个 rail,所以只需要经过 L 层次的 switch,减少了路由延迟。
diff -bur folderA/ folderB/
-r 表示递归,-b 表示忽略空白字符,-u 表示输出统一样式(也就是 git diff 常见的样式,会比默认样式容易阅读)。
为什么有些会生成 at::cuda 名字空间的函数,有些不会?(待解决)
本文说明了 m.impl("index_put.out", ...) 到 at::native::index_put 的调用路径。结合
PyTorch C++ 函数派发 中 at::native::index_put_ → at::_index_put_impl_ → index_put_stub 的调用路径,补全了从 m.impl 到 stub 的全路径。
本文说明了 m.impl / at::cuda::index_out → index_stub 的调用路径。准确来说是介绍了 at::cuda::index_out 调用 meta 和 impl 的过程,meta 中对下标做预处理(包括 kBool 转 kLong 下标),impl 中调用 index_stub 进行计算。和 index_out 不同,index_put_ 函数没有出现在 at::cuda 名字空间中,取而代之的是 at::cuda::_index_put_impl_。
在这两个例子中,能找到的函数有:
理解 native_functions.yaml 中的函数定义在哪里
非 structured 情况:
- func: index_put_(...)
dispatch:
CompositeExplicitAutograd: index_put_ # 默认名字空间是 aten
\ at::index_put_ (build/aten/src/ATen/Functions.h)
\ at::_ops::index_put_::call (build/aten/src/ATen/OperatorsEverything.cpp)
\ c10::Dispatcher::singleton()
| .findSchemaOrThrow(index_put_::name, index_put_::overload_name)
| .typed<index_put_::schema>().call
|struct TORCH_API index_put_ (build/aten/src/ATen/MethodOperators.h)
| ... name = "aten::index_put_";
| ... overload_name = "";
\ m.impl("index_put_", ...) (build/aten/src/ATen/RegisterCompositeExplicitAutogradEverything.cpp)
\ at::native::index_put_ (aten/src/ATen/native/TensorAdvancedIndexing.cpp)
\ at::_index_put_impl_
结论是按照 dispatch: yy: xx 字段生成 at::xx 函数,最终调用到 at::native::xx 函数。
^^^^^^^^^^^^^^
如果是 structured: True,就对应 at::native::structured_xx::impl,在代码中通常为
at::native 名字空间下的 TORCH_IMPL_FUNC(xx)。
^^^^^^^^^^^^^^^^^^^
如果是 structured_delegate: zz,可能得去找 zz 的定义。
所有的 stub 定义几乎都在 aten/src/ATen/native/DispatchStub.h 文件,可以慢慢看。里面有段注释:
// Implements instruction set specific function dispatch.
//
// Kernels that may make use of specialized instruction sets (e.g. AVX2) are
// compiled multiple times with different compiler flags (e.g. -mavx2). A
// DispatchStub contains a table of function pointers for a kernel. At runtime,
// the fastest available kernel is chosen based on the features reported by
// cpuinfo.
//
// Example:
//
// In native/MyKernel.h:
// using fn_type = void(*)(const Tensor& x);
// DECLARE_DISPATCH(fn_type, stub)
//
// In native/MyKernel.cpp
// DEFINE_DISPATCH(stub);
//
// In native/cpu/MyKernel.cpp:
// namespace {
// // use anonymous namespace so that different cpu versions won't conflict
// void kernel(const Tensor& x) { ... }
// }
// REGISTER_DISPATCH(stub, &kernel);
//
// To call:
// stub(kCPU, tensor);
//
// TODO: CPU instruction set selection should be folded into whatever
// the main dispatch mechanism is.
//
// Supported device types for registration:
// - CPU: Central Processing Unit
// - CUDA: NVIDIA GPUs
// - HIP: AMD GPUs
// - MPS: Apple Silicon GPUs (Metal Performance Shaders)
// - MTIA: Meta Training and Inference Devices
// - XPU: Intel GPUs
// - HPU: Reserved for HPU (Intel Gaudi) device types
// - PrivateUse1: Reserved for private/custom device types
//
// If you want to update the list of supported devices, add a new dispatch_ptr
// member in DispatchStubImpl.h and update the get_call_ptr switch.
// As well you will need to update the inlined list in 'is_device_supported`
//
//
// ignore warnings about DispatchStub::DEFAULT, AVX, AVX2 defined elsewhere
DispatchStub 模板基类定义
见 aten/src/ATen/native/DispatchStub.h。DispatchStub 类型为:
template <typename rT, typename T, typename... Args>
struct DispatchStub<rT (*)(Args...), T>;
其中主要包含几类方法,一是调用,会根据设备类型来选择函数指针,强制转换后调用: